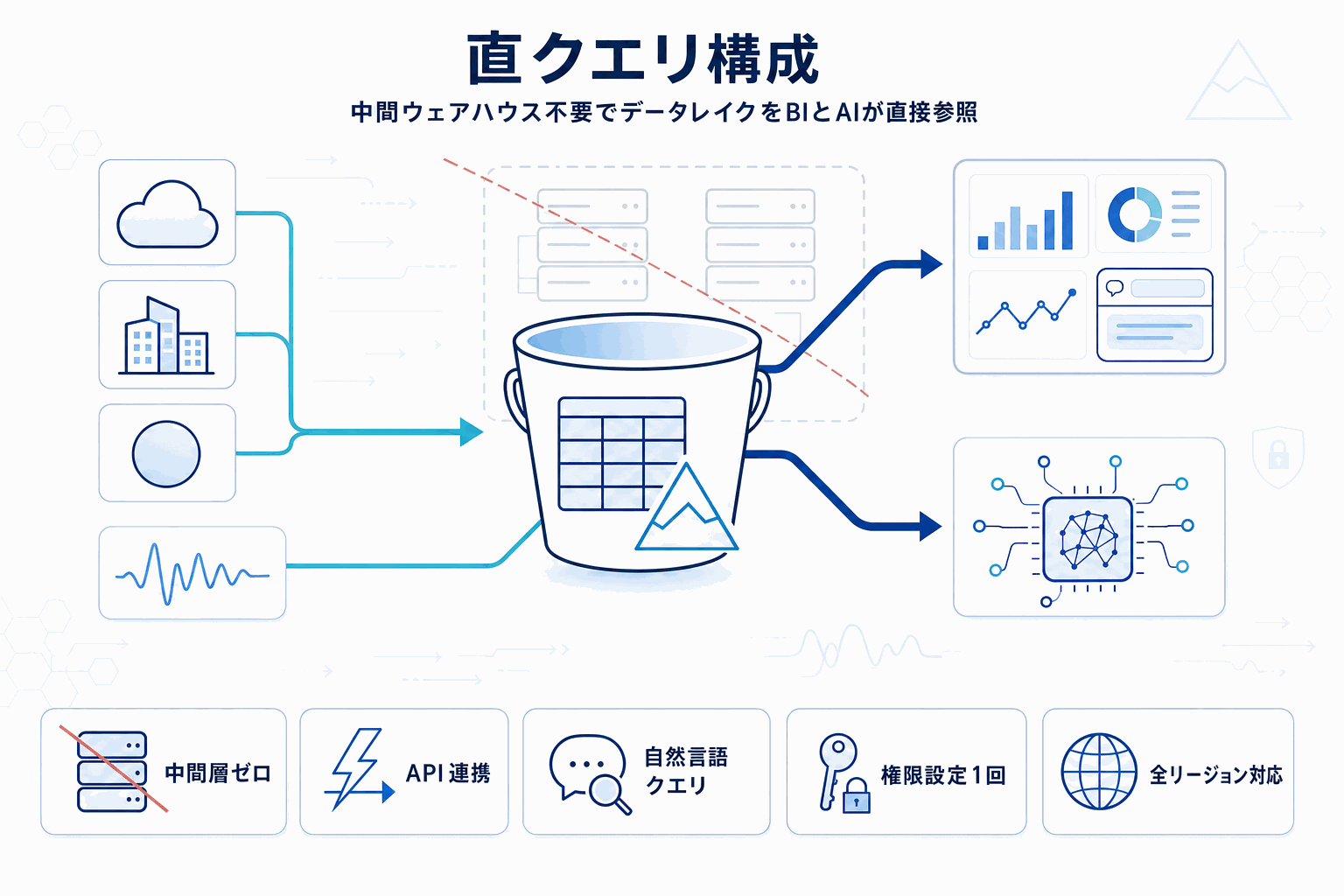
Amazon Quickが、Amazon S3テーブルバケットをデータソースとして正式にサポートした。S3テーブルバケットはApache Icebergテーブルをマネージドに保持する仕組みで、これまでBIツールで可視化する際はAthenaやRedshiftなど別のクエリエンジン/ウェアハウスを経由する構成が一般的だった。今回の対応により、Quickからこれらのテーブルへ直接クエリでき、ダッシュボード・会話型分析・Dataset Q&Aのすべてで同じデータを参照できる。
構成上の要点は3つある。第一に、中間ウェアハウスやOLAPレイヤーを前提としない接続経路が公式に用意されたこと。第二に、Salesforce、SAP、Amazon Kinesis Data FirehoseからS3テーブルバケットへのZero-ETL連携と組み合わせることで、外部SaaSや逐次データを含むほぼリアルタイムの分析が、最小限のパイプラインで成立すること。第三に、管理者がS3テーブルバケットの権限を一度設定すれば、作成者側はすぐデータセットを作成してビルドを開始できる運用フローが示されたことである。
読者の意思決定に直結する論点は、既存のレイクハウス構成の見直し余地である。Redshift+QuickSight のような「BI側にウェアハウスを挟む」従来型と、S3 Tables直クエリ型のどちらを採るかは、クエリ並列性・コスト・他エンジンからの利用といった条件で結論が変わる。公開情報の範囲ではパフォーマンス数値は示されていないため、既存テーブルで自社ワークロードを実測する必要がある。
また、Dataset Q&Aがデータレイクを真実源として自然言語質問に応答できる点は、エージェント型AIの実装設計に影響する。BIとAIエージェントで別々のデータコピーを持つ必要が減り、権限境界の定義点もS3テーブルバケット側に集約しやすくなる。導入を検討するチームは、まず1テーブルで接続と応答精度を試し、既存構成との差分を記録するところから始めるのが現実的である。