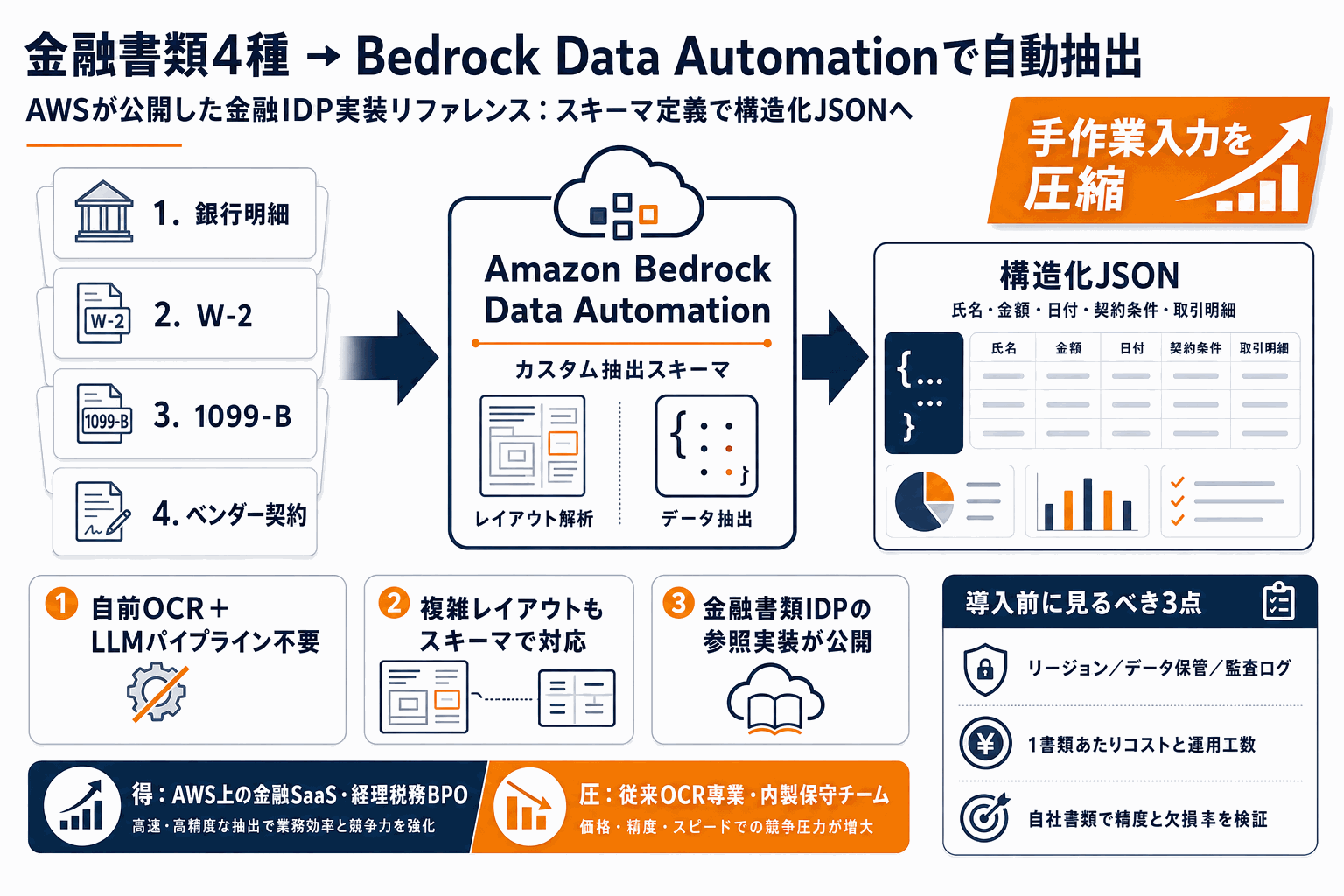
何を題材にした記事か
AWS Machine Learning Blogが公開した本記事は、Amazon Bedrock Data Automation(BDA)を用いて4種類の金融書類から情報を抽出する実装例をまとめたものだ。対象は銀行明細(bank statements)、W-2フォーム、1099-B税務フォーム、ベンダー契約(vendor contracts)の4種で、いずれもレイアウト・項目数・自由記述の比率が異なる代表的な書類群である。記事は各書類の複雑性(complexity)を整理した上で、BDAのカスタム抽出(custom extraction)をどう設定したか、そして抽出結果がどうだったかを順に示す構成になっている。
なぜ「4種まとめ」の事例提示が効くのか
金融・経理領域のIDP(Intelligent Document Processing)は、書類1種ごとにテンプレートを作り込む従来のOCR運用と、汎用LLMにプロンプトで抽出を任せる新しい運用の間で実装方針が揺れている。BDAはこの中間で、スキーマを定義すれば構造化JSONが返るマネージド型のアプローチを取る。AWSが今回、米国の税務(W-2/1099-B)と汎用業務(銀行明細・契約)を1記事で並べたのは、「書類が変わってもスキーマ設計で対応できる」というBDAの設計思想を読者に体感させる狙いがある。逆に言えば、本記事はカスタム抽出スキーマの書き方が肝で、ここを写経できるかが採用判断の分かれ目になる。
日本企業が読むときの落とし穴
W-2と1099-Bは米国固有の様式で、日本企業がそのまま流用できる書類ではない。読者が転用するなら、源泉徴収票・支払調書・銀行通帳明細・取引基本契約書といった日本固有の様式に対し、記事のスキーマ設計の考え方(フィールド粒度・繰り返し項目の扱い・自由記述欄の分離)を移植する作業が必要になる。また、BDAの対応リージョンと、抽出ログ・元ファイルの保管場所が監査要件を満たすかは、PoC着手前に必ず確認しておきたい点だ。