この研究は、LLMが推論ベンチマークで高い最終回答精度を出しても、プロンプトで指定された手順を最後まで忠実に実行できるとは限らない、という問題を正面から測定したものだ。
実験設計は意図的にシンプルで、単純な算術演算のみを使う。そのうえでアルゴリズムの長さと、途中で計算した中間変数を後段で参照する「ルックバック依存」の度合いを動かして難度を調整している。こうすることで、数学の難しさではなく「手順の長さと参照構造」だけが評価対象になる。
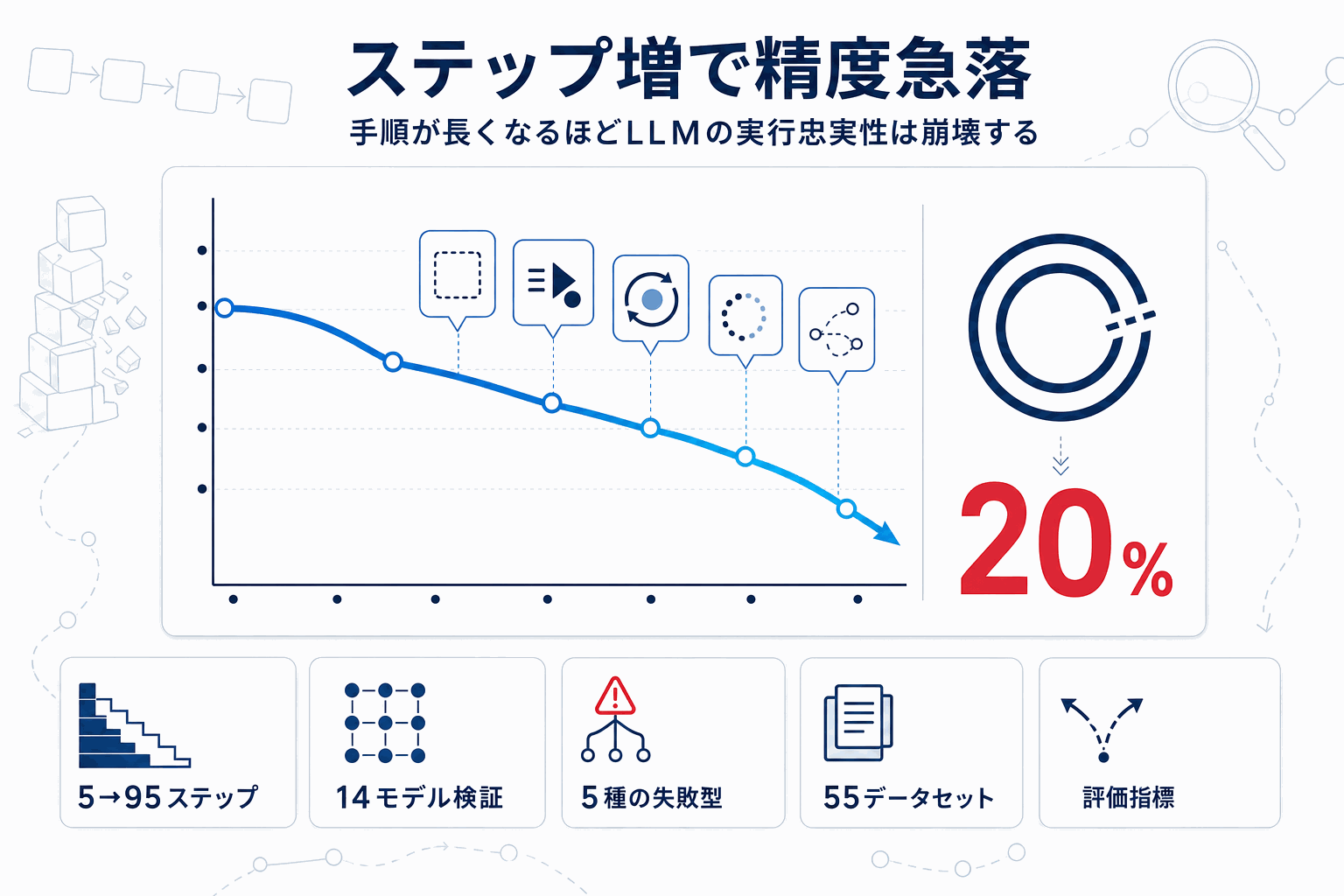
結果は、5ステップでの平均正答率61%が、95ステップで20%まで低下するというものだった。14モデル・55データセットという広い対象で観測されているため、特定モデルの癖ではなく、現行LLM全般に共通する性質として読める。
加えて、生成レベルの分析で失敗が5類型に整理されている点が実務上有用だ。回答欠落、早期回答、初回エラー後の自己修正、実行不足のトレース、幻覚的な余分ステップ。これらは生成ログを見れば検出できるため、評価パイプラインや本番監視に組み込みやすい。
日本の開発現場への含意は明確で、エージェントやワークフロー自動化の導入可否を判断する際、ベンチマーク総合スコアだけでなく、自社タスクの典型ステップ長における成功率と失敗パターンの内訳を測る必要がある。長手順は分割する、外部ツールで状態を持つ、といった設計判断の根拠として参照できる一次情報である。