
PDFから文章・表・画像を読み順と座標付きで抽出する無償OSSOpenDataLoader PDFがGitHub Trendingで1日あたり573スター増と急上昇している。Markdown/JSON/HTML形式で出力でき、200件の実在PDFでの評価で総合精度0.907、表の抽出精度0.928を1位と主張する。高速な確定的ローカル処理と、複雑なページだけをAIに回すハイブリッド方式を持ち、OCRを内蔵して80以上の言語と低品質スキャンに対応する。
注目の核は、AIへのデータ取り込み(RAG前処理)と、画面読み上げ対応のタグ付きPDF自動生成という2つの実需を、Apache 2.0の無償ライセンスで1つにまとめた点だ。Python・Node.js・Javaから使え、LangChain連携も備える。タグなしPDFのタグ付きPDFへの自動変換は無償だが、PDF/UA規格への完全変換と視覚編集は企業向け有償オプションで、Word/Excel/PowerPoint処理やGPU動作には非対応。
X上では表崩れ解決への好意的な反応が中心だが、「毎秒60ページ」「doclingより38倍速」という主張に対し、PyMuPDFとの実測比較で再検証する声もある。
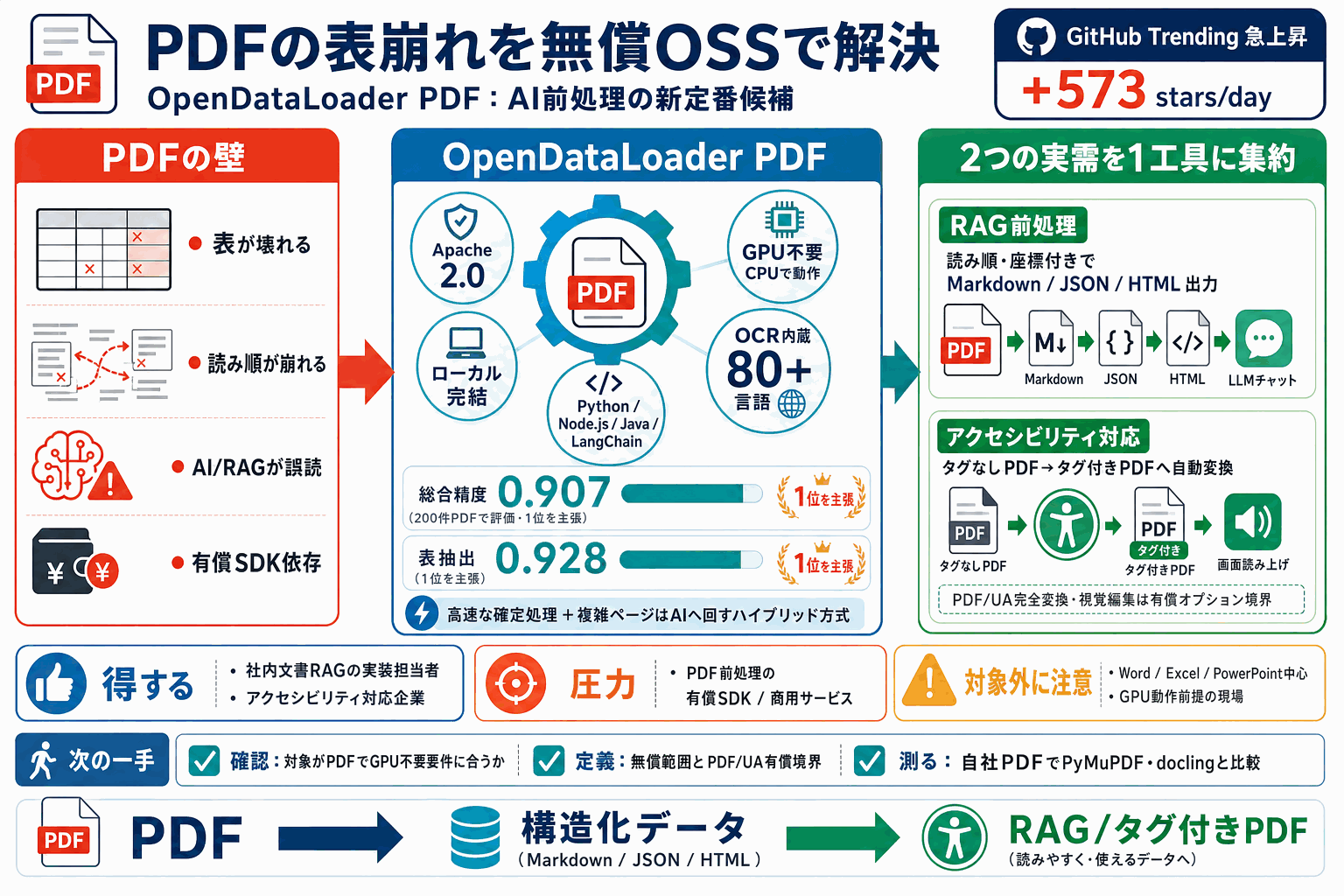



■ 3. PDF→Markdown変換OSS「OpenDataLoader」がベンチ1位 表も見出しもそのままMarkdownに変換する完全無料・完全ローカルのOSS。CPU onlyで毎秒60ページ以上処理。doclingより38倍速く、markerよりGPU不要で精度が高い。GitHubスター2万超、Apache 2.0。
PDFを1秒で100ページ読める無料ツールが普通にやばい。 その名もOpenDataLoaderPDF。 PDFをChatGPTやClaudeが読みやすい形に変えてくれるツールなんだけど、 副業やってる人ほど知っておいた方がいい。 すごいのは速さだけじゃなくて、