
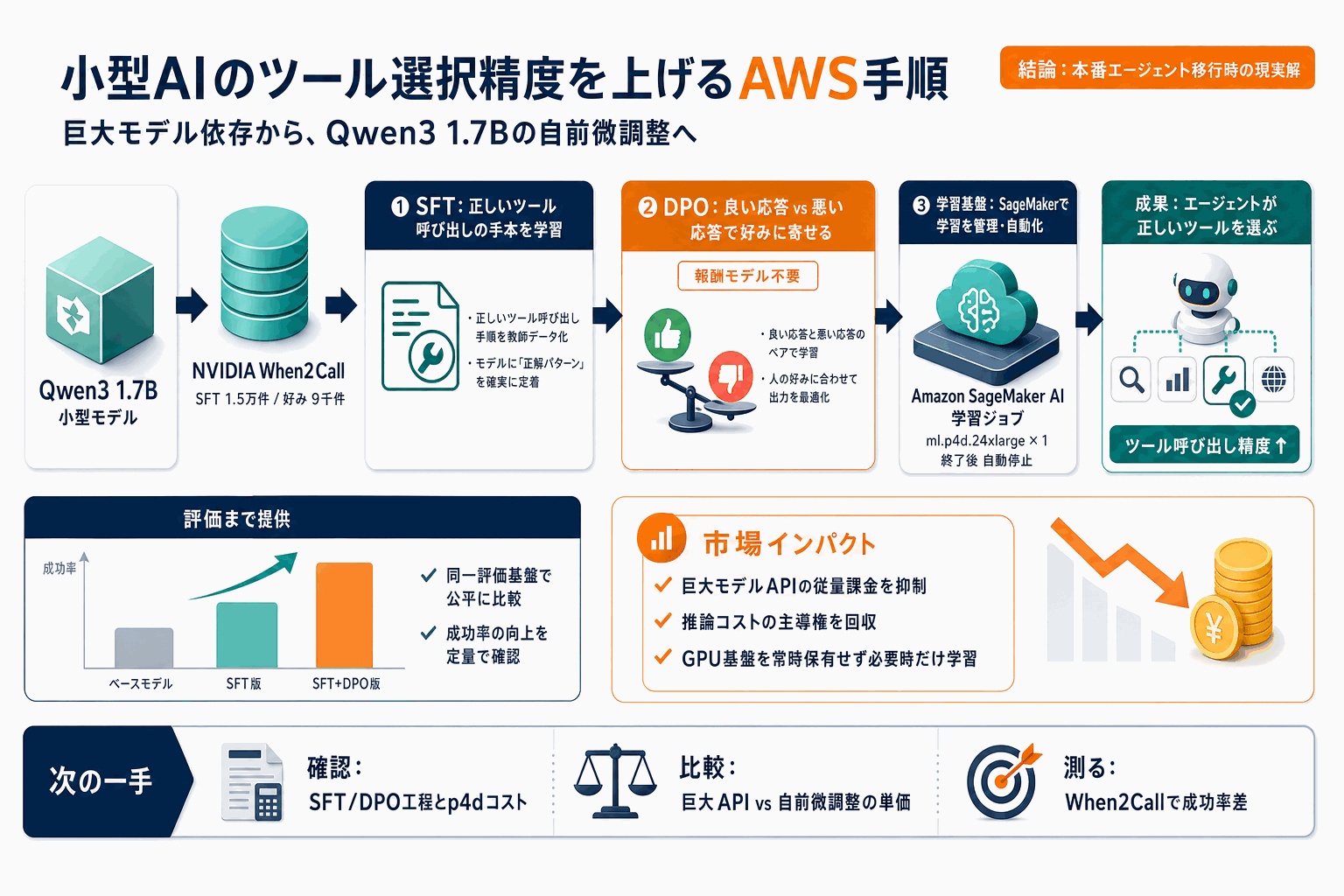
AWSが、AIエージェントが正しいツールを呼び出す精度を、巨大モデルへの依存ではなく小型モデルQwen3 1.7Bの微調整で上げる手順を公開した。手本を学ばせる教師あり微調整(SFT)で基礎を作り、良い応答と悪い応答の比較から好みを学ばせるDPO(好み最適化)で望ましい振る舞いへ寄せる二段構えが核だ。DPOは報酬モデルを使う強化学習と違い比較データだけで学べるため、計算資源と学習時間を抑えられる。
学習と評価にはNVIDIA公開のWhen2Call(SFT用1万5千件、好み用9千件、テスト用)を使う。学習はAmazon SageMaker AIの学習ジョブでml.p4d.24xlargeインスタンス1台を使い、指標はMLflowに記録される。終了後は資源を自動停止でき、自前の学習基盤を抱えずコードに集中できる。
手順はベースモデルと複数の微調整版を同じテストデータで比較し、データに基づき品質を判断する評価工程まで含む。試験導入から本番運用へエージェントを移す企業にとって、推論コストの主導権を取り戻す現実的な選択肢になる。


More info about Search as Code in the Perplexity Agent API docs: