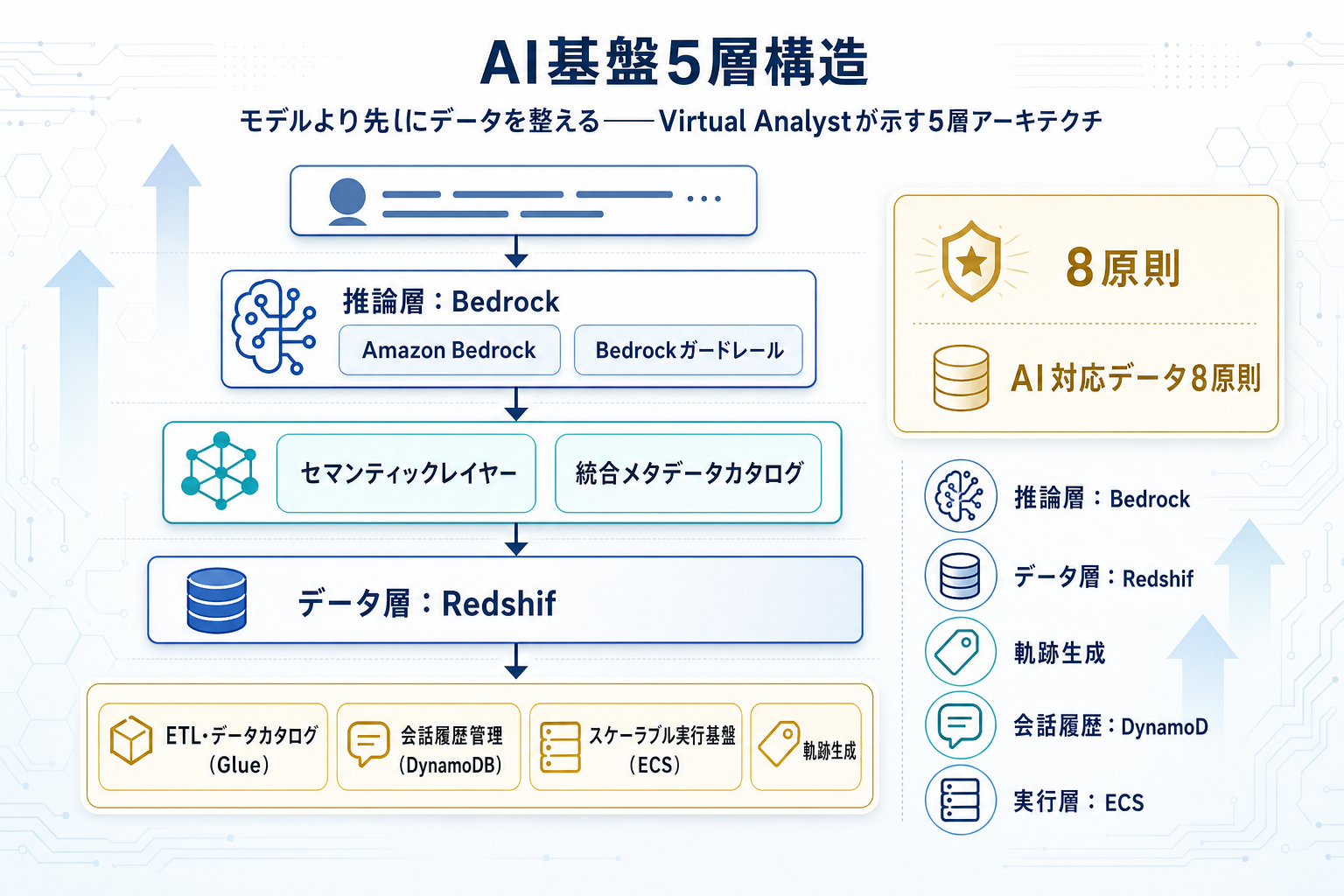
AWSのMachine Learningブログは2026年4月29日、米資産運用大手Vanguardが社内向けAIアシスタント「Virtual Analyst」を構築した過程を公開した。記事の主眼は、どのLLMを選ぶかではなく、AIに渡す前のデータをいかに整えるかに置かれている。
提示された「AI対応データ」の8指針には、データ製品と運用モデルの明確化、ガバナンスとセキュリティの定義、技術メタデータとビジネスメタデータを統合するカタログの構築、セマンティックレイヤーの実装などが含まれる。これらは特定企業固有のノウハウではなく、エンタープライズでAIを業務に組み込む際の汎用フレームとして整理されている。
実装面ではAmazon Bedrockを生成AIの中核に据え、データ層にAmazon RedshiftとAWS Glue、状態管理にAmazon DynamoDB、実行基盤にAmazon ECSを組み合わせた構成が示された。個別サービスの目新しさよりも、既存サービスを業務要件に沿って束ねる設計判断と、データエンジニア・ビジネスアナリスト・コンプライアンス・セキュリティ・業務担当者による横断的な協働モデルが確立された点に重心がある。
日本の読者にとっての意味は明快だ。金融・保険・製造などの規制産業でAIを導入する際、PoCの失敗要因の多くはモデル精度ではなくデータの意味定義とガバナンスに帰着する。Vanguardの事例は、その順序を逆転させずに進めた実装録として、経営層・アーキテクト・実装者それぞれの判断材料になる。特にセマンティックレイヤーの位置づけは、LLMがビジネス用語を誤解しないための実務的な回答として参照価値が高い。