AWSは2026年4月30日、機械学習ブログで『Organizing Agents' memory at scale: Namespace design patterns in AgentCore Memory』を公開した。同日に公開された『Amazon Bedrock AgentCore Memory: Building context-aware agents』と合わせ、Bedrock上でエージェントの長期記憶を構築する際のリファレンス設計が揃った形になる。
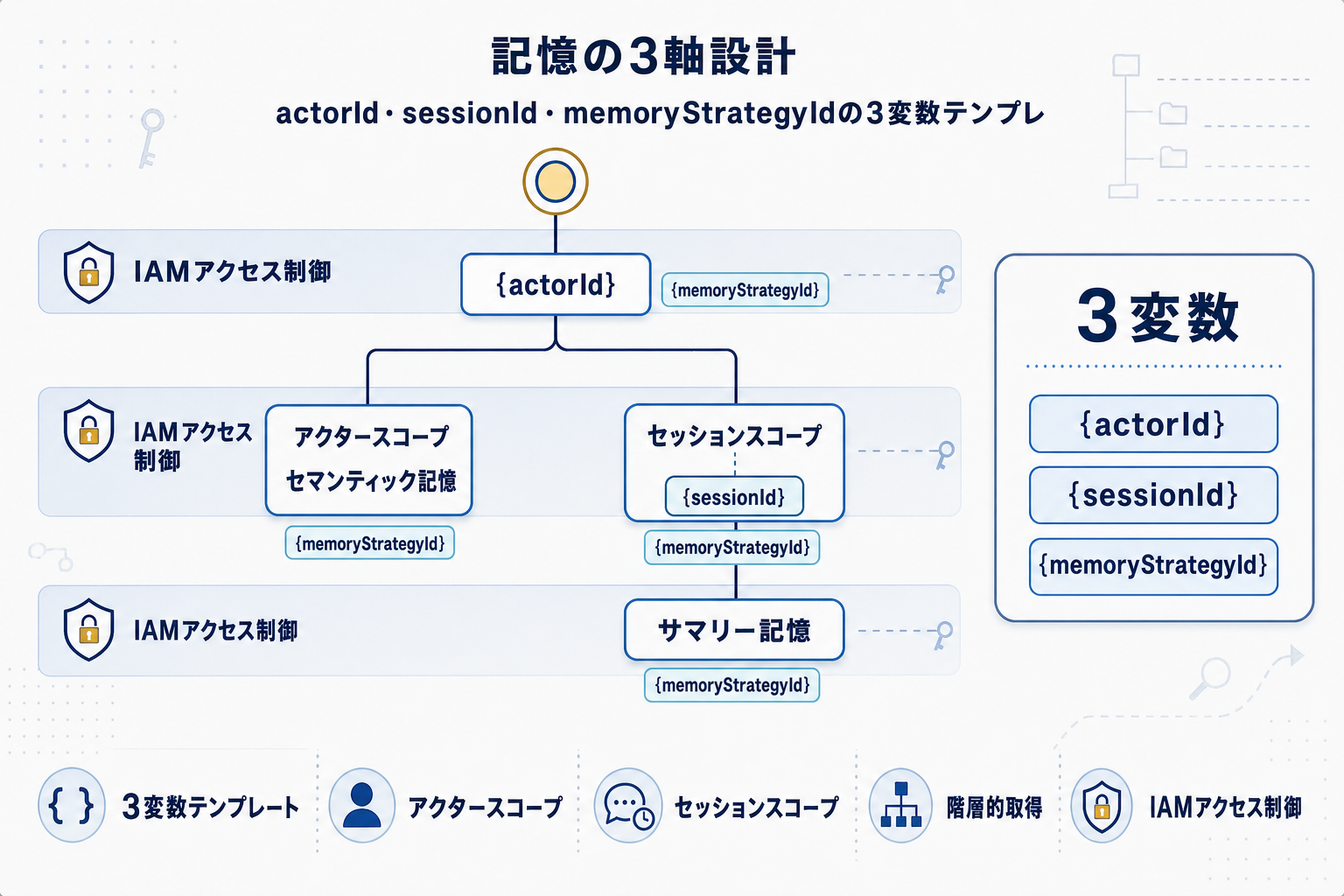
AIエージェントの実装で繰り返し問題になるのが、記憶の混線だ。複数ユーザーが同じエージェントを使う場合、あるユーザーの会話履歴や個人情報が別ユーザーの応答に紛れ込むと、プロダクトとして成立しない。さらに組織アカウント単位、セッション単位、共有ナレッジ単位で記憶のスコープを切り分ける必要があり、実装者は毎回キー設計から考えることになる。
ネームスペース設計パターンは、この分離を階層構造で表現する考え方を提示する。ユーザーID・テナントID・セッションIDといった軸を組み合わせて記憶の住所を決めることで、取得時のスコープが構造で担保される。同時にGitHub(awslabs/agentcore-samples)でチュートリアルが提供されており、コードレベルで挙動を確認できる。
日本企業にとっての実装判断ポイントは二つある。ひとつは、マネージド記憶層を使うことで自前でVector DB+セッションストア+パーミッション管理を組む工数をどこまで削減できるか。もうひとつは、ネームスペース設計が自社の個人情報保護・監査要件に耐えるかどうか。特にBtoB SaaSでマルチテナント対応を進める現場では、記憶のスコープが監査ログ上で明示できる設計は要件適合の重要な材料になる。まずチュートリアルで挙動を測り、自前実装との比較軸を言語化する段階に入った。