AWSは2026年4月29日、Amazon Nova 2 Sonicを用いて既存のテキストエージェントを会話型音声アシスタントへ移行する設計ガイドをMachine Learning Blogで公開した。記事はテキストと音声の要件差、アーキテクチャの分解、ツール・サブエージェントの再利用、システムプロンプトの適応までを実務視点で整理している。
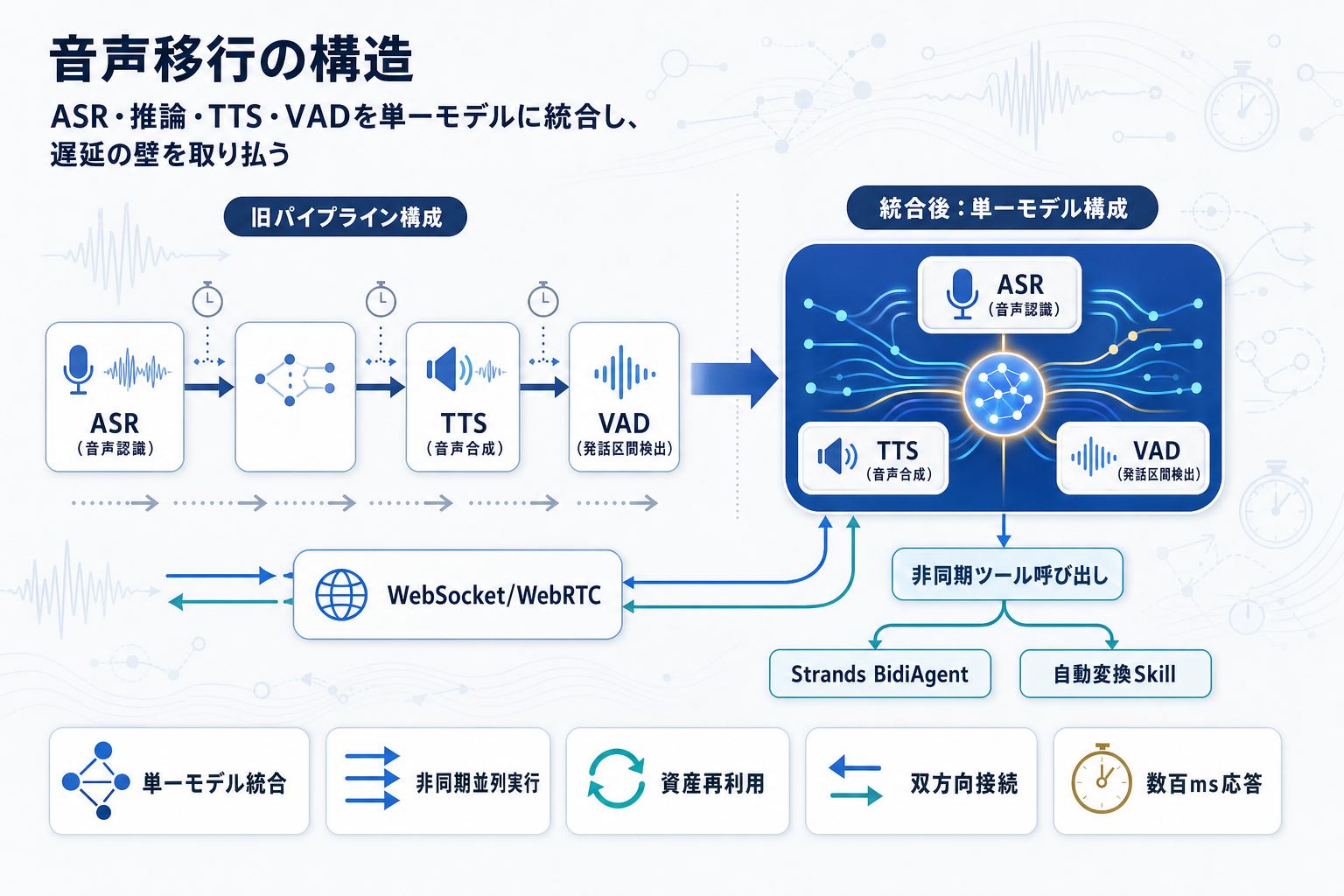
音声エージェントの本質的な難しさはレイテンシにある。数百ミリ秒以内に初応答を返さなければ会話が不自然になり、数秒の沈黙は通話切断と誤認される。従来のASR→LLM→TTSというパイプライン構成では各段の遅延が累積するため、Nova 2 SonicはASR・推論・TTS・VAD(発話区間検出)を単一モデルに統合することでこの境界を圧縮している。
もう一つの鍵が非同期ツール呼び出しである。ツール実行中も会話を継続しながら複数ツールを並列実行できるため、DB検索や外部API呼び出しで発生する「待ち時間の沈黙」を設計で回避できる。
実装面では、テキストエージェントから音声エージェントへの自動変換Skillがサンプルリポジトリで公開されており、KiroやClaude Codeから利用できる。一方でクライアント層はWebSocket/WebRTCによる双方向接続が前提となるため、StreamlitなどでPoCを作ったチームはReactなどへの書き直しが必要になるケースがある。プロンプト・ツール・サブエージェントといったテキスト側資産は再利用可能だが、クライアント層と応答設計は音声固有の再設計が避けられない点を、移行コスト見積もりに織り込む必要がある。