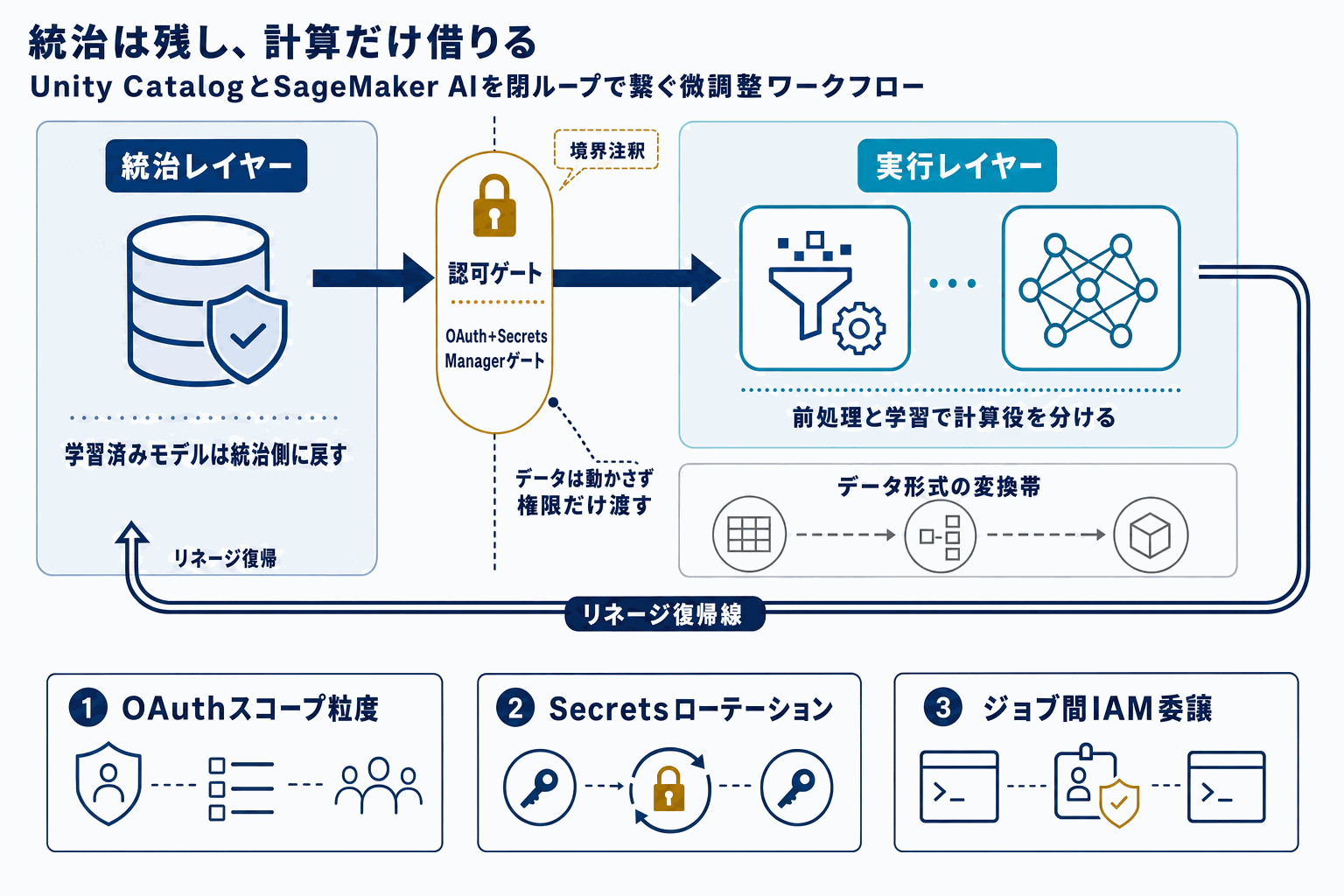
AWSがMachine Learning Blogで公開した「Fine-tune LLM with Databricks Unity Catalog and Amazon SageMaker AI」は、Databricks Unity Catalog(UC)で管理されたデータを、Amazon SageMaker AIのファインチューニングジョブから利用する実装手順をまとめた記事である。題材LLMはMistralの「Ministral-3-3B-Instruct-2512」で、Hugging Faceにモデルカードが公開されている小型モデルだ。
ポイントは、データガバナンス層(Unity Catalog)と学習実行層(SageMaker AI)を分離したまま接続している点にある。Unity Catalogは行・列レベルの権限管理とリネージを持つため、学習データを別バケットに複製せず、権限境界を保ったまま学習ジョブへ供給する構成は、社内データの出所説明や監査対応を求められる企業にとって重要な参照点になる。
もう一つの実務的価値は、aws-samplesリポジトリに実装ノートブック(LLM_Finetunig_SageMaker_AI_Unity_Catalog.ipynb)が同時公開されていることだ。ブログ本文の概念説明だけでなく、コードレベルで追試できるため、PoCの初動を短縮できる。
読者が押さえるべき落とし穴は3点。第一に、UC側のサービスプリンシパル権限とSageMaker実行ロールの境界設計を最初に固めないと、ジョブ実行時に権限エラーで止まる。第二に、Ministral-3-3Bは小型モデルゆえ評価指標の取り方を間違えると改善幅が見えにくい。第三に、ブログ/ノートブックには具体的なコスト数値の公開がないため、学習時間とインスタンス種別から自前で見積もる必要がある。Databricks単独またはSageMaker単独での同等構成と、データ移動コスト・監査ログ要件・運用人員の3軸で比較してから着手したい。