
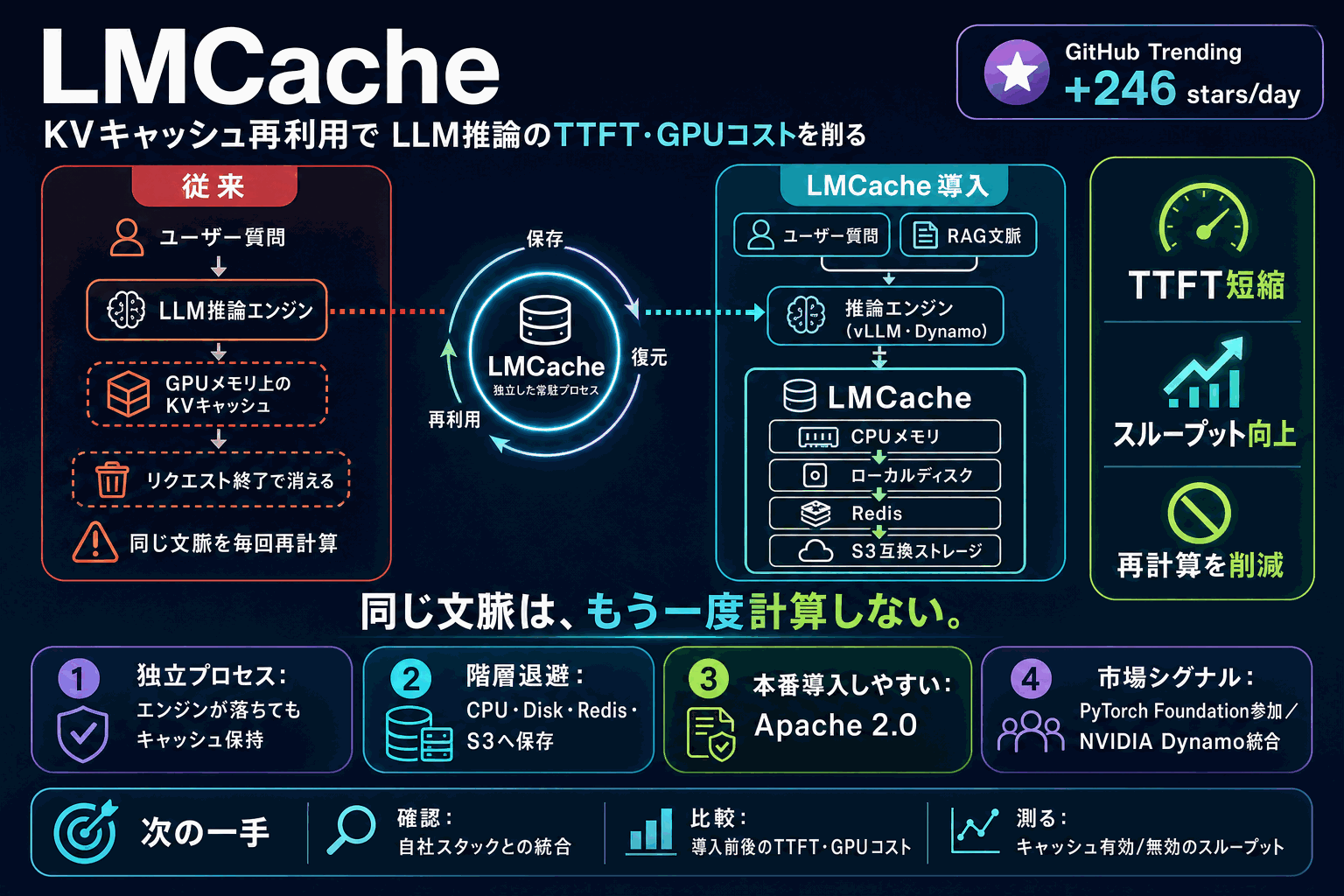
LLM推論で生成される中間データ(KVキャッシュ)を再利用して応答開始時間を短縮するOSS「LMCache」が、GitHub Trendingで本日1日あたり246スター増のペースで急上昇している。リポジトリは「LLMのための最速のKVキャッシュ層」を掲げる。
従来のKVキャッシュは推論エンジンのGPUメモリ上に一時的に置かれ、リクエスト終了とともに消えていた。LMCacheはこれを推論エンジンとは独立した常駐プロセスで管理し、CPUメモリ・ローカルディスク・Redis・S3互換ストレージへ階層退避して再利用する。エンジンが落ちてもキャッシュが残る設計で、RAGや対話エージェントなど同じ文脈を繰り返す用途でTTFT(応答開始時間)短縮とスループット向上に直結する。
2025年10月にPyTorch財団のエコシステムへ参加し、NVIDIAの推論基盤Dynamoとも統合された。技術は論文(arXiv:2510.09665)で公開され、ライセンスはApache 2.0。特定ベンダーに依存せず推論エンジンやストレージ間でキャッシュを使い回せるため、LLMを本番運用する企業の基盤部品になりつつある。


MLSys初日は招待講演中心。vLLMへのAIツールからのPR問題、LLMマルチエージェントのverificationオーバーヘッド問題や、LMCacheの紹介、GPU MODE創業者によるGPUカーネルコードをAI生成させるときの信頼性問題などについて話を聴いた。