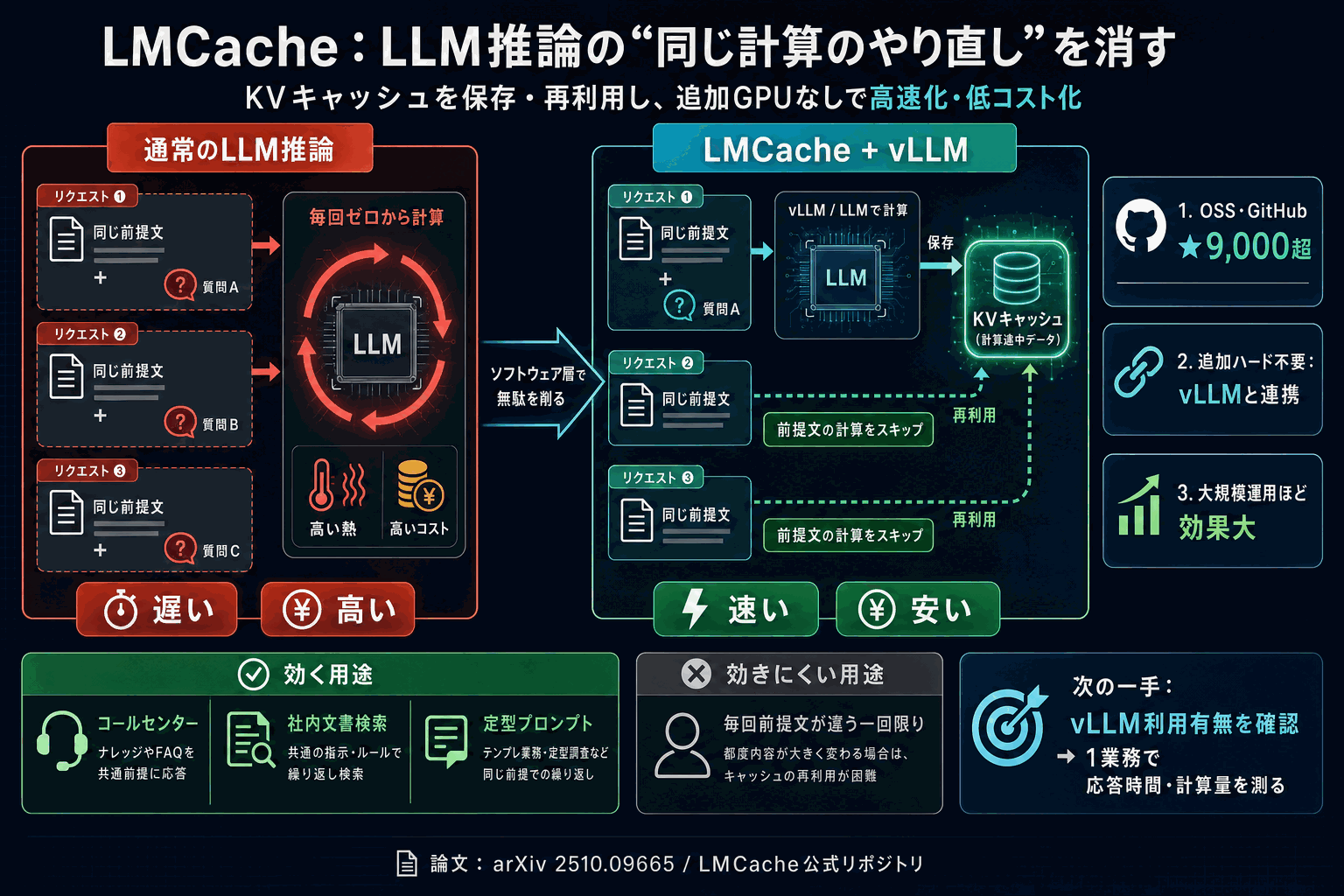
LLMを自前のサーバーで運用する現場の「遅い・高い」という課題を、計算結果の再利用で解消するオープンソースLMCacheが注目を集め、GitHubの星が9,000を超えた。一度処理した内容を賢く再利用し、毎回ゼロから計算し直すことを避けるしくみである。
LMCacheが再利用するのはKVキャッシュと呼ぶ計算途中の中間状態だ。LLMは長い前提文を毎回先頭から計算し直すことが多く、これが応答の遅さとコスト増を招く。とくに同じシステムプロンプトや定型指示を繰り返す業務利用では、同一計算の無駄が積み重なる。LMCacheはこの中間状態を保存・再利用する層を、推論エンジンvLLMと組み合わせて提供する。
論文(arXiv 2510.09665)は、これを企業規模のLLM推論向けの効率的なキャッシュ層として位置づけている。追加のGPUを買わずソフトウェア層で無駄を消すため、リクエスト規模が大きく共通の前提文を繰り返す運用ほど効果が大きい。GitHubでの高い注目度は、コスト削減を求める運用現場の関心の強さを反映している。