
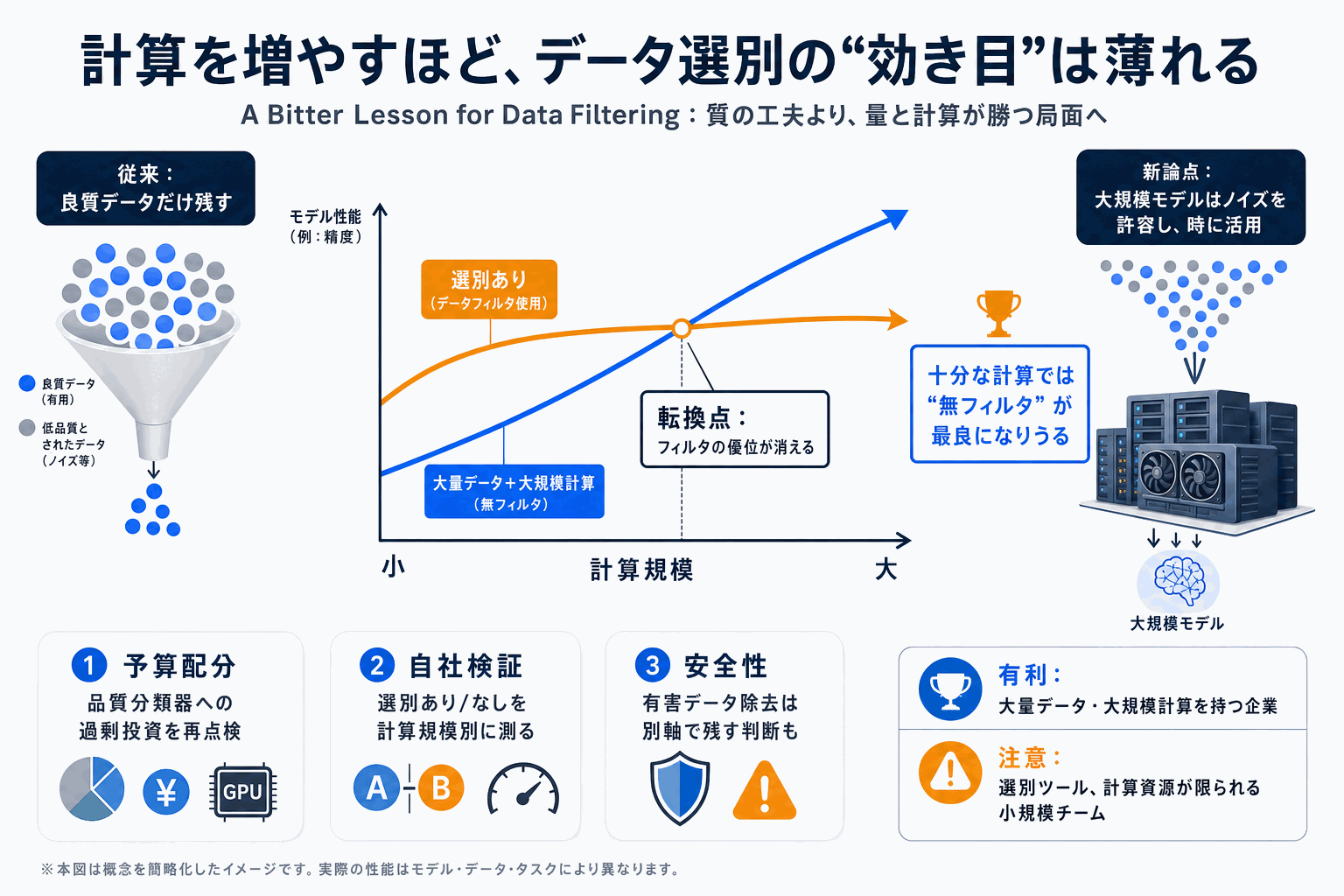
学習用データを事前に選別して品質を高める手法が、計算資源を増やすほど有効性を失うとする論文「A Bitter Lesson for Data Filtering」(arXiv番号2605.19407)がarXivで公開された。論文はAI研究の経験則『苦い教訓』をデータ前処理に当てはめ、人手や分類器で良質データだけ残す工夫より、より多くのデータと計算資源を投入する方が長期的に勝ると主張する。
紹介投稿は「十分な計算があれば、言語モデルにとって最良のデータ選別は無選別になりうる」「大規模モデルは名目上の低品質データをかなり許容し、時に恩恵すら受ける」と要点を述べる。DiggはStanfordの研究者による公開とし、「高計算・データ希少な条件下で大規模モデルが選別なしでも改善する」と報じた。
ただしX上では「小規模データと単純な選別ヒューリスティックでしか検証されていない」との前提限定の指摘もある。自社モデルを学習・微調整する企業にとっては、品質分類器への投資配分とデータ量・計算資源の配分を見直す材料となる。安全性目的の有害データ除去とは目的が異なるため、一括りにしない判断が要る。



A Bitter Lesson for Data Filtering