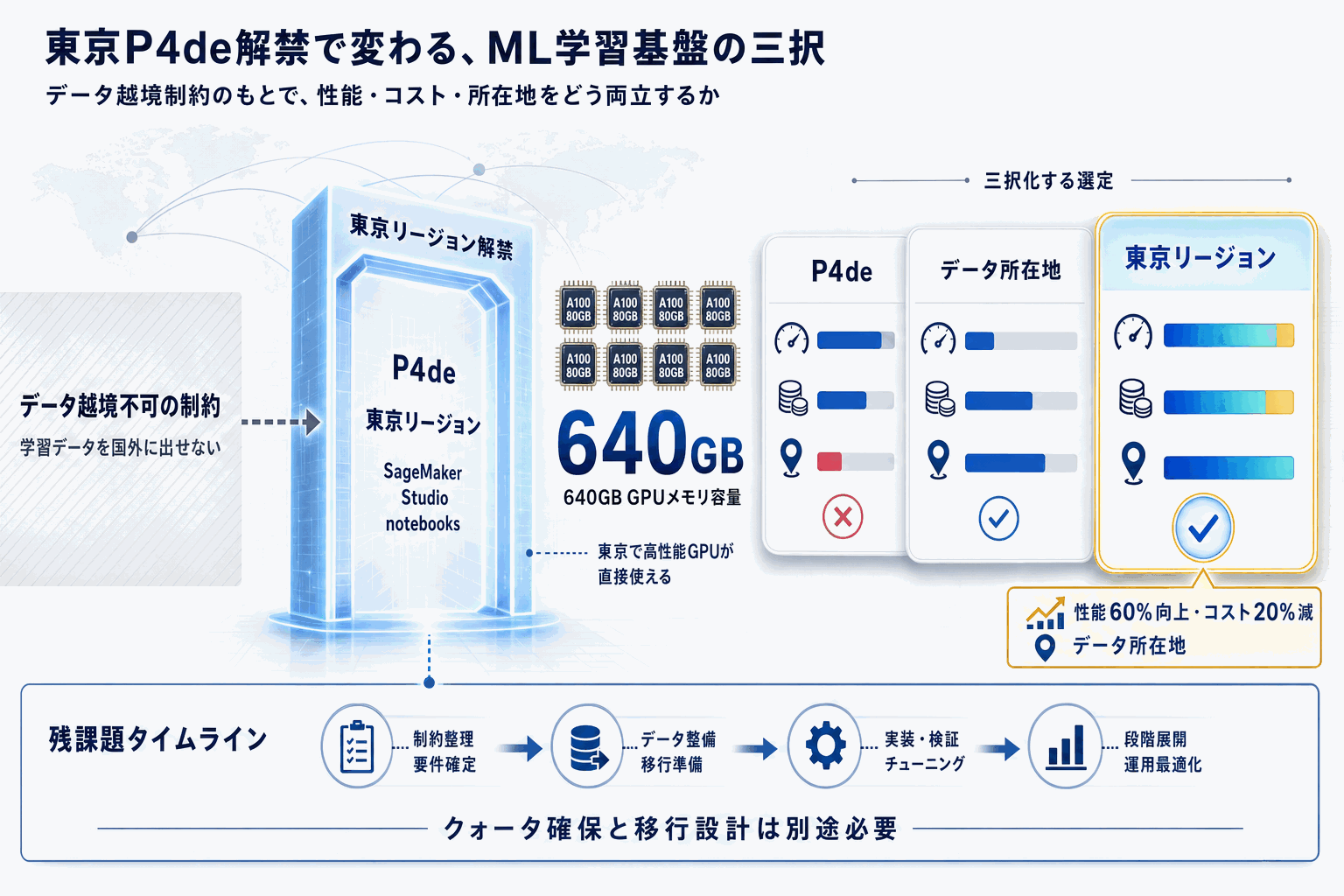
AWSは、SageMaker Studio NotebooksにおけるP4deインスタンスの利用可能リージョンを拡大したと発表した。P4deはNVIDIA A100 80GB GPUを8基搭載するインスタンスファミリーで、大規模言語モデルの事前学習や微調整、画像生成モデルのトレーニングなどメモリ集約的なワークロードに用いられる。
SageMaker Notebooksでのml.p4d/ml.p4de/ml.inf1対応自体は2023年5月から段階的に行われてきた経緯があり、今回はStudio Notebooks(旧Notebook Instancesから刷新されたWeb IDE環境)における提供地域の追加という位置づけになる。Studioからの起動が可能になることで、ユーザーは別途トレーニングジョブを定義することなく、対話的なノートブック上でA100 80GBを直接呼び出して試行錯誤ができる。
日本のチームにとっての論点は、追加された対象リージョンに東京(ap-northeast-1)や大阪(ap-northeast-3)が含まれるか否かである。データレジデンシー要件を持つ金融・医療・公共領域では、学習データを国外に出さずにP4deを使える選択肢が広がるかが導入判断の分岐点となる。公式What's Newに掲載された対応リージョン一覧の確認が前提作業になる。
GPU調達難が続く中で、Studio経由でP4deに到達できる経路が増えること自体が、AWSを利用する研究開発チームにとってのキャパシティ確保の選択肢拡大につながる。既存のP3やG5系で間に合わせていたワークロードをP4deに載せ替えた際のスループットとコスト効率は、自チームのモデルサイズで実測しないと判断できない。まずは小規模なジョブで起動可否と単価を確認したうえで、本格的な置き換えのROIを評価する手順が現実的である。