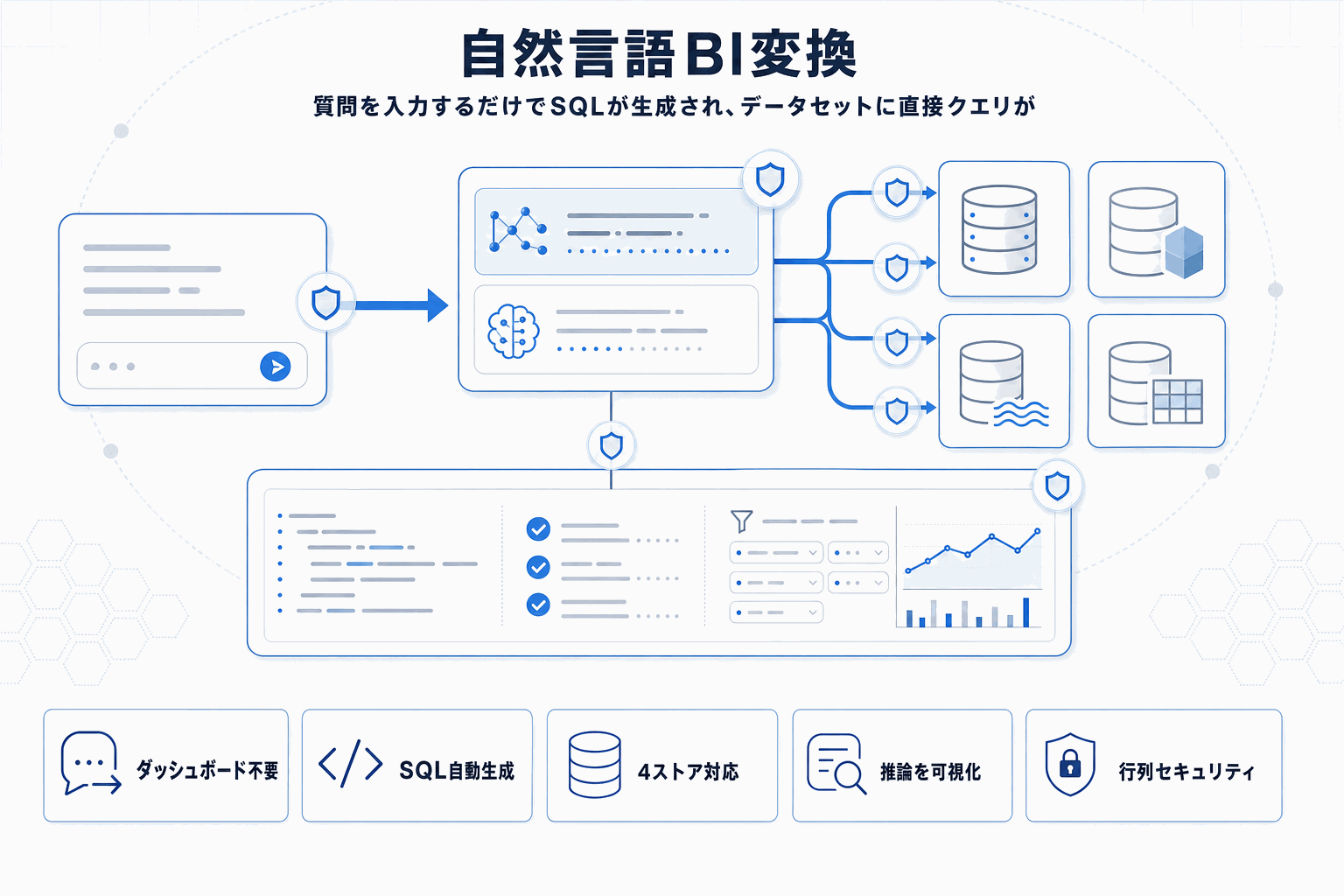
Amazon QuickSightに追加されたDataset Q&Aは、従来のQuickSight Q(ダッシュボード前提の自然言語インターフェース)と異なり、ダッシュボードを構築していないデータセットに対しても直接質問できる点が中心的な変化である。対応範囲はSPICEに加え、Amazon Redshift、Athena、Aurora PostgreSQL、S3 Tablesへのダイレクトクエリで、行サンプリングやデータ上限なしに数百万行規模のデータセット全体をクエリできるとされる。
精度面ではDataset Enrichmentが鍵になる。YAML・JSON・プレーンテキスト形式でビジネス用語、指標定義、同義語などをデータセットに直接アップロードでき、エージェントが自然言語を正しいカラムと集計に橋渡しする材料を整えられる。自社のKPI定義がSQLに反映されるかは、このEnrichmentの記述品質に左右される。
説明責任の観点ではChat Explainabilityが重要だ。生成されたSQL、エージェントの仮定、適用されたフィルターをステップごとに確認できるため、非技術系ステークホルダーに対しても「なぜこの数字が出たか」を提示できる。行/列レベルのセキュリティはDataset Q&A経由でも自動適用されると案内されており、権限境界を越えた参照を防ぐ。
日本企業への含意は、QuickSight Enterprise Editionを既に導入しているデータ基盤チームにとって、アドホック依頼対応の工数削減とセルフサービスBIの裾野拡大が現実的な選択肢に入ることだ。一方、Standard Editionや他BI主体の組織では、エディション要件・既存BI投資・S3 Tables採用状況を踏まえた比較が必要になる。