AWSはAmazon Quickに、自然言語でエンタープライズデータへ直接問い合わせできるDataset Q&Aを追加し、Amazon Quickが提供される全AWSリージョンで一般提供を開始した。既存のDashboard Q&Aがダッシュボード上の可視化済みデータを対象にしていたのに対し、Dataset Q&Aはデータセットそのものを対象にするため、アドホックな探索的分析までカバー範囲が広がる。
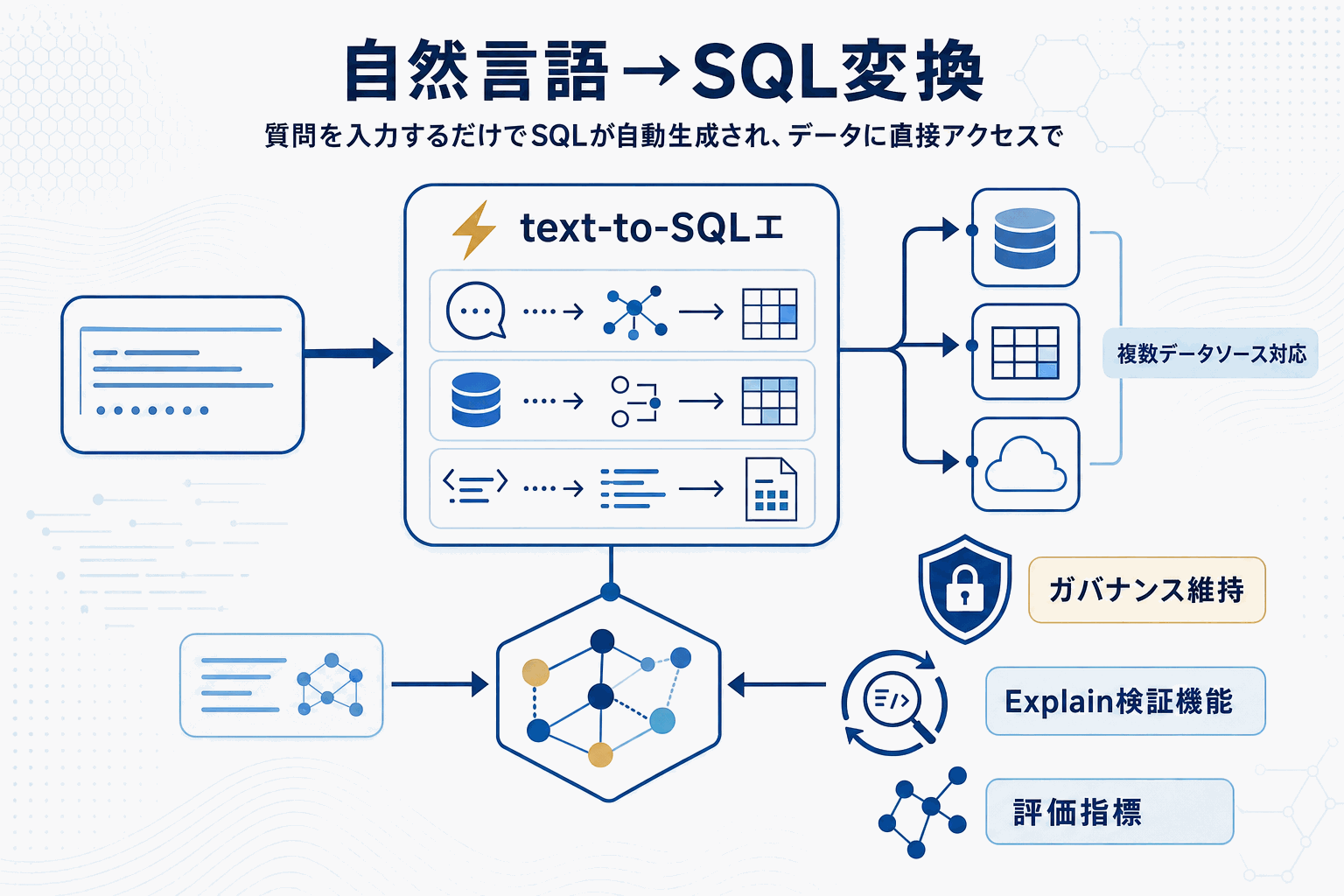
中核はtext-to-SQLエージェントで、1回の会話ステップの中で質問解釈・対象データ特定・方言別SQL生成を完結させる。対応範囲はSPICEに加え、Amazon Redshift、Amazon Athena、Aurora PostgreSQL、Amazon S3のテーブルバケット上のApache Icebergテーブルで、各エンジンの方言に最適化したSQLを生成する。データオーナーはカスタム指示・ビジネス定義・フィールド説明をQuickに直接入力、またはファイルアップロードで追加でき、これらはデータセットメタデータとともにナレッジグラフへ取り込まれる。オーケストレータはこのグラフを用いて関連データセットを特定し、SQLの精度を担保する。
業務利用で重要なのは統制と検証の経路である。Row Level SecurityとColumn Level Securityを含む既存ガバナンスポリシーは引き続き適用される。加えてExplain機能により、生成されたSQLの推論ロジックをユーザーが段階的に確認でき、結果を業務に使う前にクエリの妥当性を検証できる。対応する質問タイプはトレンド分析、時系列比較、ランキング、複合条件の分析、オープンエンドな探索的質問まで広い。
AWSデータ資産を既に採用する組織にとっては、追加移行なしで自然言語分析をビジネスユーザーに開放できる点が実務的に効く。一方で、ビジネス定義の整備とExplainによる検証運用を伴わない導入は、生成SQLの誤りを見逃すリスクを残すため、PoC段階で質問セットを定め生成SQLの正答率と介入回数を測ることが評価の起点になる。