Hugging Faceは2026年5月15日、ブログ「Unlocking asynchronicity in continuous batching」を公開し、transformersライブラリのcontinuous batchingに非同期I/O層を追加した設計を解説した。前回記事「Continuous Batching」で示された、ステップ単位でリクエストを入れ替える基本機構の続編にあたる。
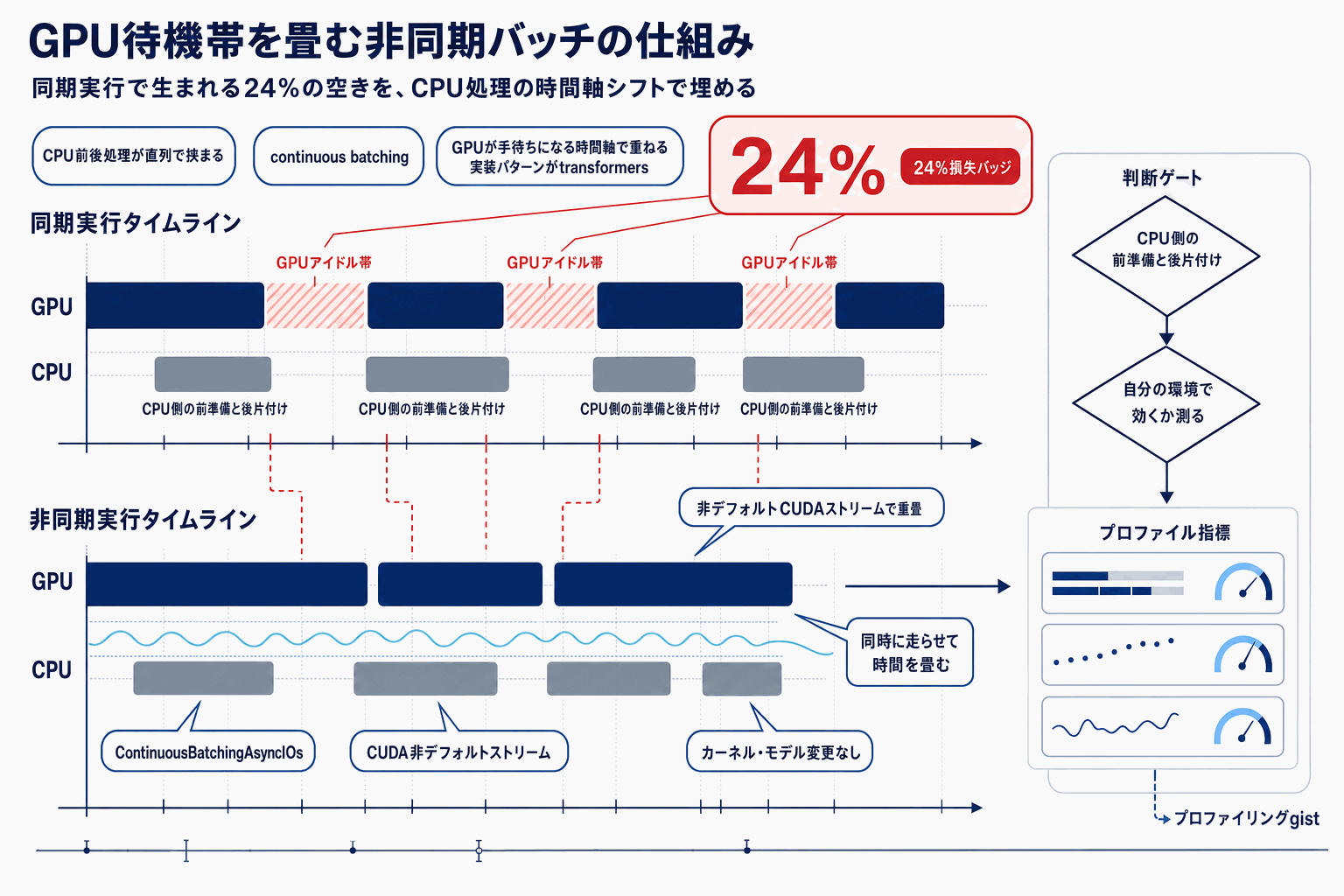
継続バッチ方式の課題は、GPUがステップを終えた直後にCPU側のトークナイズ・デトークナイズ・スケジューリングが直列で挟まり、その間GPUがアイドルになる点にある。今回追加されたContinuousBatchingAsyncIOsは、入出力処理を非同期化してGPU実行と時間軸で重ねることで、この空き時間を埋める構造を取る。実装はtransformersリポジトリのcontinuous_batchingディレクトリ配下、continuous_api.pyとinput_outputs.pyに含まれる。
読者目線で重要なのは、専用推論サーバー(vLLM、TGIなど)に移行せずとも、transformers本体のAPIで継続バッチ+非同期I/Oを試せる点だ。研究用コードから本番推論まで同一スタックで通したいチーム、推論サーバーの運用負荷を最小化したいチームにとって、移植コストを払わずスループットを伸ばす選択肢が増えた意味は大きい。
一方で、ブログとコードだけでは自社ワークロードでの実利得は分からない。プロファイリング用のgistスクリプトが併せて配布されているため、まずは自前環境でGPU稼働率・p99レイテンシ・バッチ占有率を測り、専用推論サーバーとの差を数値で押さえることが現実的な次の一手となる。落とし穴として、CPU側処理が軽いワークロード(短い入出力・小バッチ)では非同期化の恩恵が小さいケースがある点には注意したい。