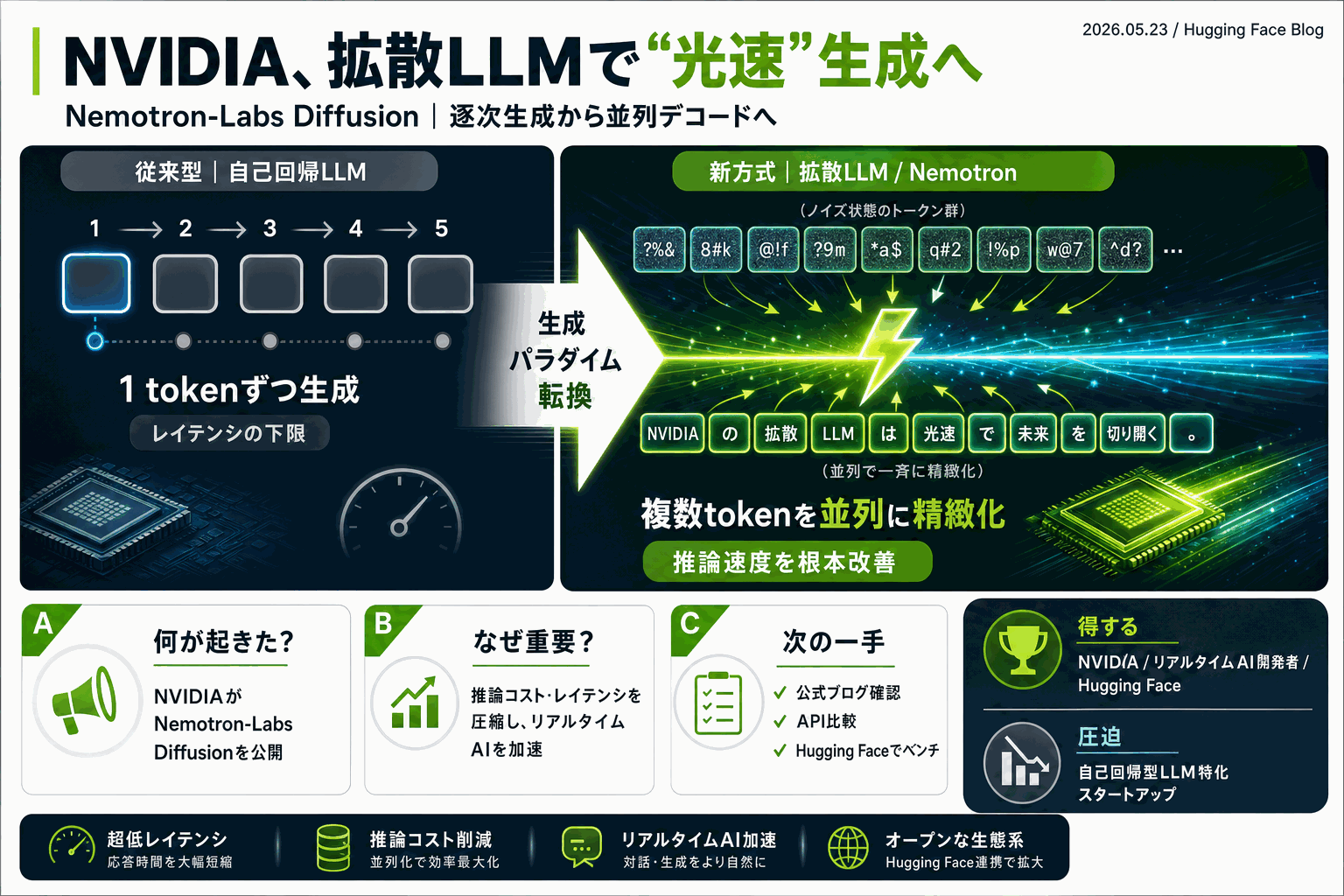
自己回帰の壁を越える「拡散言語モデル」
NVIDIAが2026年5月23日にHugging Face Blog上で公開した「Towards Speed-of-Light Text Generation with Nemotron-Labs Diffusion Language Models」は、テキスト生成の根本的な高速化を掲げる発表だ。GPT系をはじめとする現行の主流LLMは「自己回帰型(autoregressive)」と呼ばれ、トークンを1つずつ順番に生成する。この逐次性が推論レイテンシの理論的下限を決めており、どれだけGPUを高速化しても「次のトークンを待つ」構造自体は変わらなかった。
拡散言語モデル(Diffusion LLM)は、画像生成で知られるDiffusion Modelの考え方をテキストに応用したもので、ノイズ状態から複数トークンを並列に精緻化していく。タイトルの「Speed-of-Light(光速)」という表現は、ハードウェアの理論性能限界に近づくという意味で使われる業界用語であり、NVIDIAがこのアプローチで推論効率の壁突破を狙っていることを示している。
日本の開発現場への含意
NVIDIAブランドのNemotronシリーズで拡散方式を本格展開する点は、研究段階から実装段階への移行を示唆する。日本企業にとっての論点は3つある。第1に、リアルタイム音声対話・ライブコード補完など低レイテンシ要件の用途で、現行APIから乗り換える価値があるか。第2に、自社GPUインフラ(特にNVIDIA系)への最適化度合いがどこまで進んでいるか。第3に、自己回帰型と比べた出力品質・一貫性のトレードオフだ。
本ブログの公開はHugging Face上で行われており、モデル本体・コード・評価指標が同プラットフォームから入手可能な形になる。実装着手時の落とし穴として、拡散LLMはステップ数と品質のトレードオフ調整が自己回帰型と異なるため、既存の評価パイプラインをそのまま流用できない点に注意が必要となる。