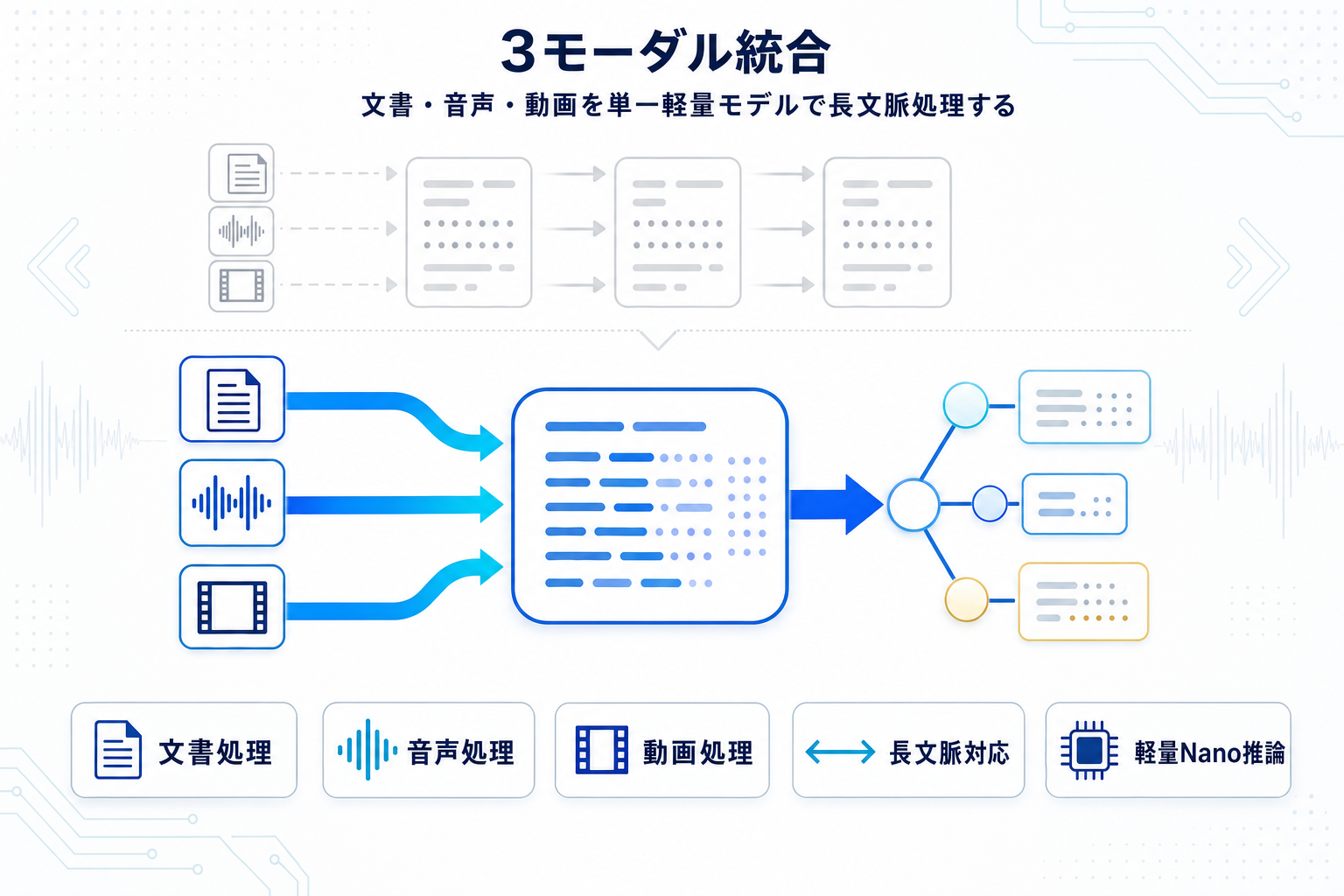
NVIDIAが「Nemotron 3 Nano Omni」と題するマルチモーダルモデルをHugging Face Blogで公開した。発表の軸は、文書・音声・動画という3つの入力モダリティを、長文脈で扱えるエージェント基盤として提供する点にある。
これまでマルチモーダルを業務に組み込む際は、OCR・音声認識・動画解析をそれぞれ別モデルで処理し、テキストLLMに統合する構成が一般的だった。単一モデルでモダリティを横断できる構成は、パイプラインの部品数を減らし、エラー箇所の切り分けや遅延の管理を単純化する方向に働く。
「Nano」という命名は、NVIDIAのNemotronファミリーで軽量クラスを指す呼称として使われてきた系譜に連なる。軽量クラスで長文脈とマルチモーダルを同時に扱う設計は、オンデバイスや社内サーバでの自前推論、あるいは大量リクエストを低単価でさばくエージェント用途を想定読者に置いていると読める。
日本の開発現場にとっての含意は二つに整理できる。第一に、議事録音声・社内文書PDF・監視動画など日本企業が抱える非構造データを、単一モデルで処理するPoCの選択肢が増える。第二に、商用マルチモーダルAPIとの実コスト比較が現実的な議題になる。まず確認すべきはHugging Face上のモデルカードに記載されたライセンス条件、対応コンテキスト長、推奨GPU要件であり、ここを押さえないまま導入検討を進めると後工程で手戻りが発生する。