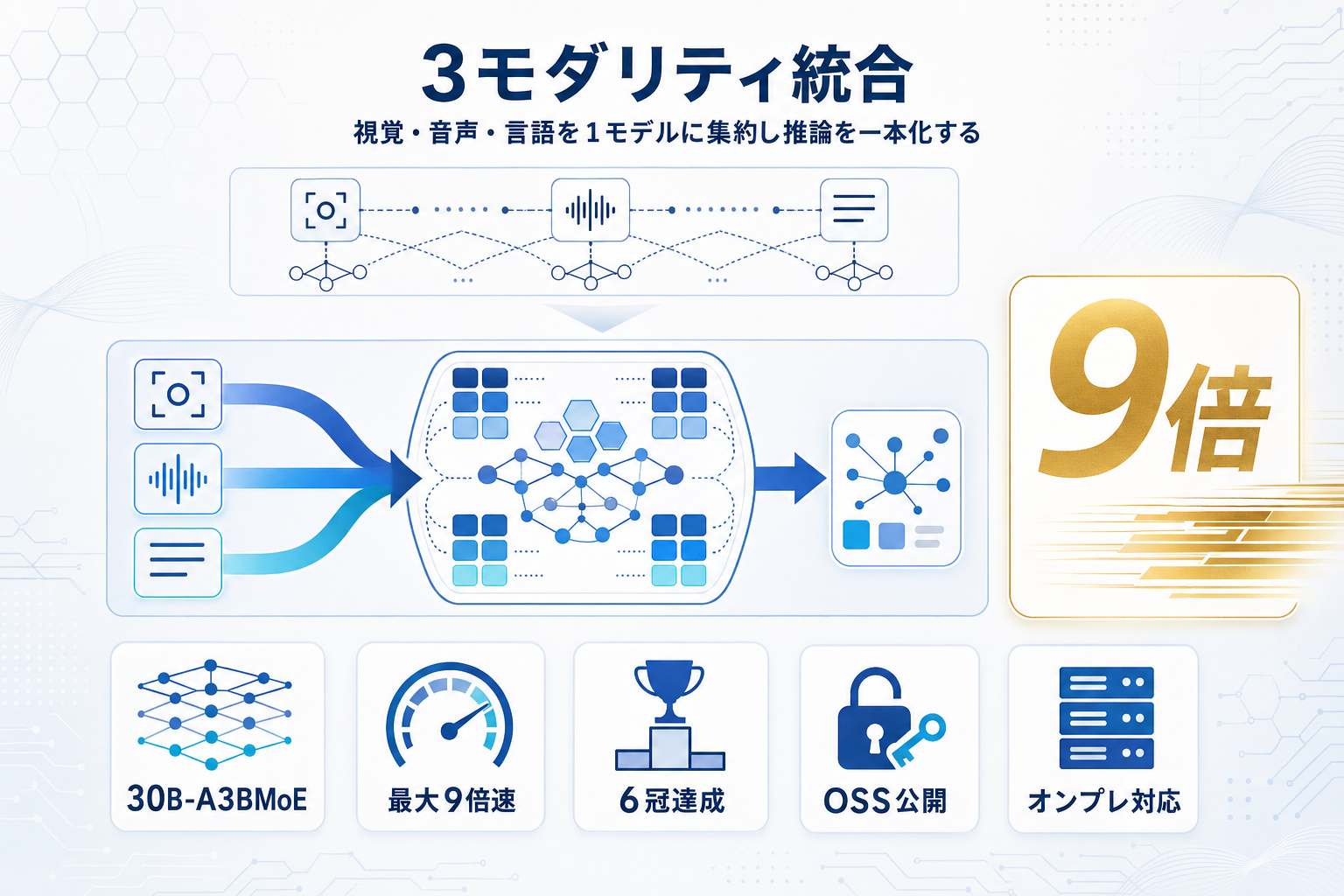
NVIDIAは2026年4月29日、視覚・音声・言語を単一モデルに統合したオープンマルチモーダルモデル「Nemotron 3 Nano Omni」を公開した。アーキテクチャは30B-A3Bのハイブリッド混合エキスパート(MoE)で、視覚エンコーダと音声エンコーダをモデル内に内包する構成を取る。
従来のAIエージェントは、視覚・音声・言語でそれぞれ別モデルを用意し、モデル間でデータを受け渡す過程でコンテキストと時間を失っていた。Nemotron 3 Nano Omniはこれを1モデルに集約することで、同等の対話性を持つ他のオープンオムニモデル比で最大9倍のスループットを達成したとNVIDIAは公表している。複雑なドキュメント解析・映像・音声理解を対象とする6つのリーダーボードでトップを記録した点も、汎用性と品質の両立を示す材料となる。
実装面では、フランスのH CompanyがOSWorldベンチマーク向けに1920×1080のネイティブ解像度でGUI操作エージェントを構築した事例が示されている。採用企業としてFoxconn・Palantir・H Company・Aibleが挙げられ、Dell・DocuSign・Oracleが評価中と位置付けられており、エンタープライズ領域での評価が先行している。
日本の意思決定者にとっての含意は明確だ。モデルの重み・データセット・学習手法はオープン公開され、Hugging Face・OpenRouter・NVIDIA NIM経由で入手できる。データ主権や監査要件が強く働く金融・公共・製造領域でも、外部APIにデータを送らない形でマルチモーダルエージェントを構築する経路が具体化した。一方で、視覚・音声・言語を個別モデルで束ねてきた既存のエージェント基盤は、単一オムニモデルを前提にしたアーキテクチャ再設計の圧力にさらされる。