
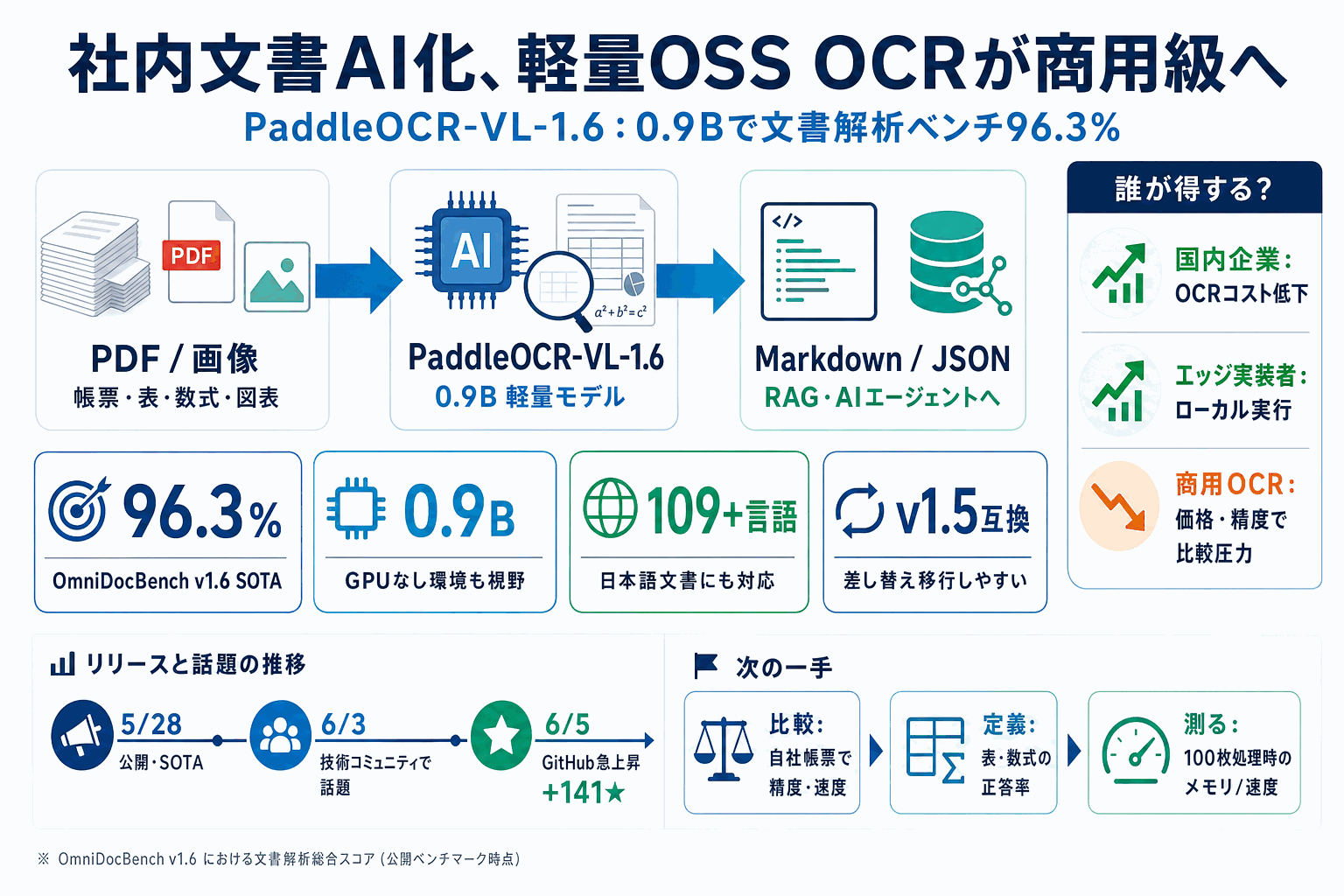
Baidu系のオープンソース文書解析ツール「PaddleOCR」が、視覚言語モデル「PaddleOCR-VL-1.6」を公開した。文書解析の標準ベンチマーク「OmniDocBench v1.6」で96.3%という新記録を達成し、テキスト・数式・表の認識でオープンソース・商用問わず首位に立った。GitHubトレンドでも本日+141スターと急上昇している。
中核モデルは0.9B(約9億パラメータ)と軽量で109〜111言語に対応し、PDFや画像をLLM向けのMarkdown/JSON形式の構造化データに変換する。GitHubでは7万件以上の評価を集め、DifyやRAGFlowなどRAG・AIエージェント構築のOSS基盤として採用されてきた。
バージョン3.6.0として2026年5月28日に公開され、前版1.5とモデル構造が完全互換のため差し替えるだけで移行できる。日本語の表・数式・図表まで扱えるため、社内文書のデータ化を低コストで進めたい企業の現実的な選択肢になる。一方で実装者からはGPU非搭載環境での実行難易度や他OCRとの精度比較といった導入実務の論点も並行して議論されている。



PaddleOCRがTrendingで4位をキープ。100言語対応・軽量OCRでPDF/画像をLLM向けJSON/Markdownに変換。高精度・PP Structure V3搭載。
PDFをPaddleOCRでスキャンできるかな? スキャンした結果からPDFから表を抜き出せるかな? って思って、手元にPythonのDocker入れて、適当なPDFスキャンさせて分かったことがひとつ。 Google NotebookLMってすごい。 ローカルLLM入れて頑張ろうという気が微塵も無くなった。格差がすごい。