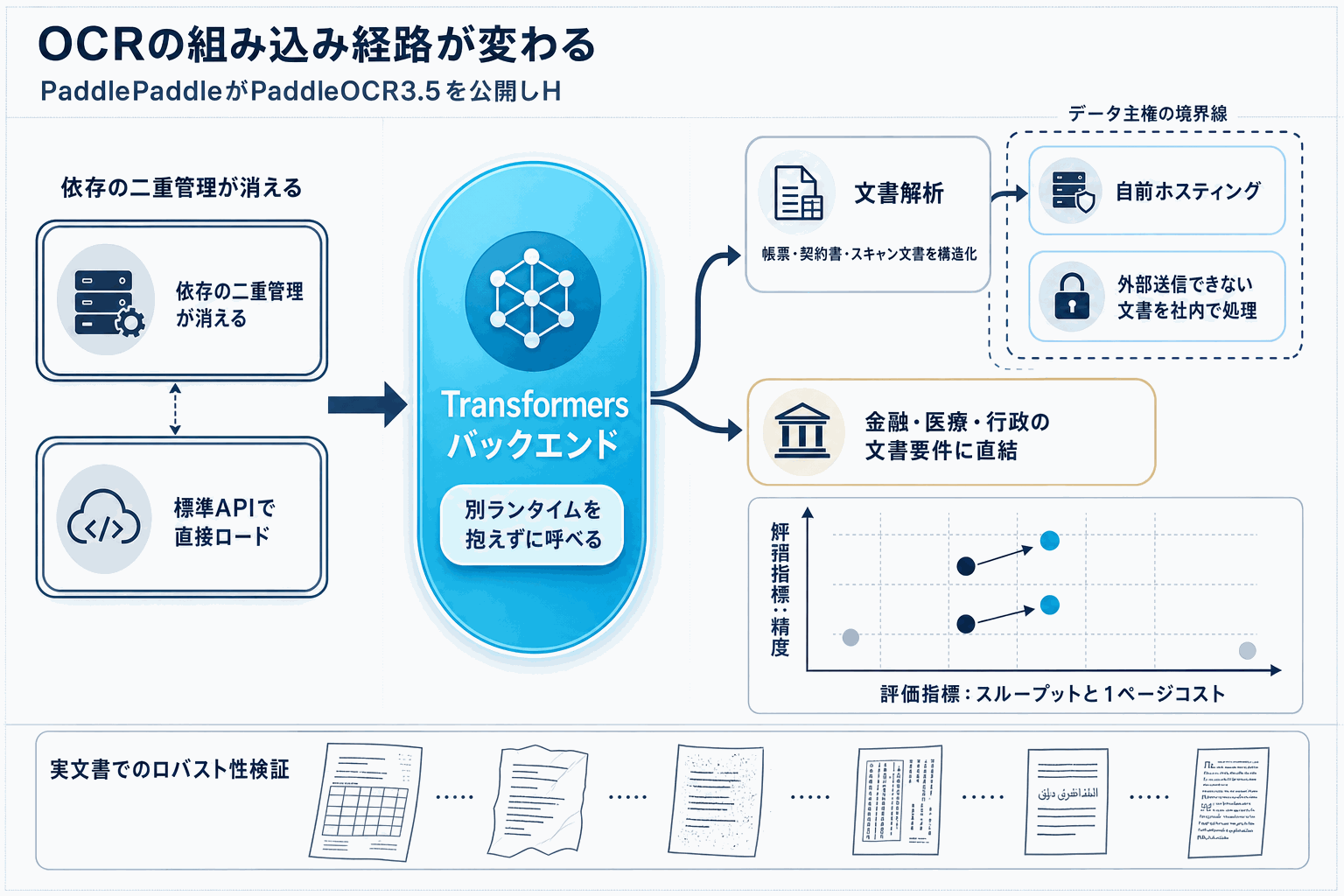
PaddlePaddleが公開したPaddleOCR 3.5は、Hugging Face Transformersをバックエンドとして用い、OCRと文書解析(Document Parsing)の両タスクを実行できる構成になった。これまでPaddleOCRはPaddlePaddleフレームワーク上での利用が前提で、PyTorch中心の開発現場では別途ランタイムを抱える必要があった。Transformersから直接ロードできるようになったことで、既存の推論パイプラインへの組み込みコストが下がる。
技術的な含意は、依存関係の単純化と運用上の一貫性にある。Transformersの標準的なロード手順とトークナイザ/プロセッサ抽象に乗ることで、モデル管理・バージョニング・サーバング基盤を他のTransformers系モデルと同じ方法で扱える。文書解析もカバーするため、単純な文字認識を超えた帳票・レイアウト処理に踏み込みやすい。
市場面では、Mistral OCRや各社クラウドの文書AIが先行するなか、自前環境で動かせるOSS選択肢の存在感が改めて押し上がる。とくに個人情報を含む文書を外部APIへ送れない金融・医療・行政・法務の現場では、ローカル実行可能なOCRの実用水準が直接的な意思決定ポイントになる。
日本の開発現場にとっては、Transformersの標準APIで呼べるという点が最大の実利だ。社内の既存PyTorchサービングに組み込み、商用APIとの精度・コスト・レイテンシを同一サンプルで比較する作業に進める。まずは代表的な帳票・契約書・スキャンPDFで成功率と崩れ方を測り、商用APIと棲み分けるかリプレースするかを定量的に判断する段階に入った。