クロス言語コードクローン検出(X-CCD)は、PythonとJava、RustとRubyのように表層が大きく異なる言語間で意味的に等価なコードを見つけるタスクであり、表面的な類似度では歯が立たない難しさがある。大規模言語モデルは意味ベースのクローン検出で有望視されてきたが、商用APIをブラックボックスとして使う運用はコスト、再現性、プライバシー、出力フォーマットの不安定さという課題を抱えていた。特に小型オープンソースモデルは、推論指向のプロンプトに従うことや、出力を二値のクローンラベルへ確実にマップすることが苦手だった。
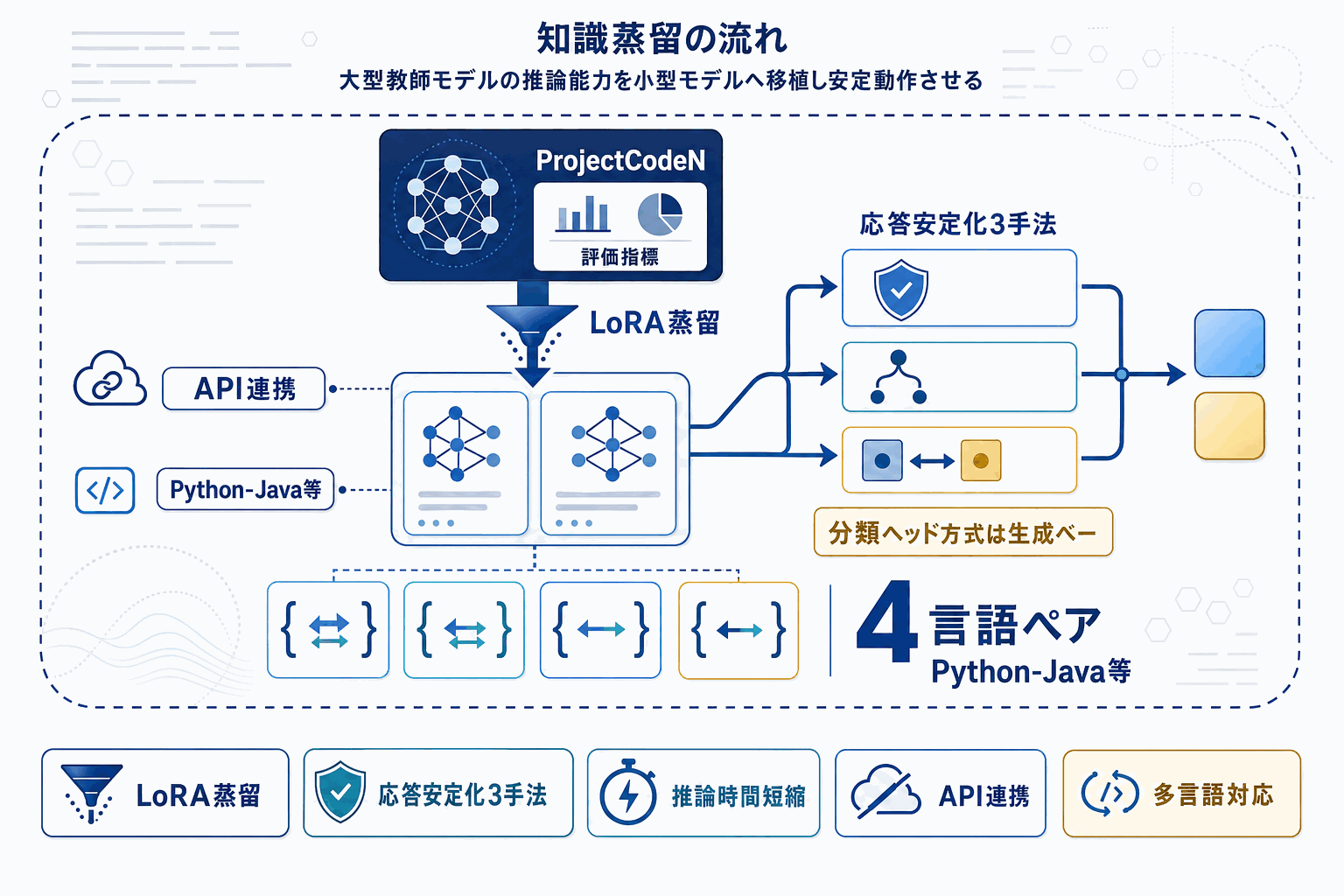
本研究はこの課題に対し、DeepSeek-R1を教師とする知識蒸留フレームワークを提案する。Project CodeNet由来のクロス言語コードペアから推論指向の合成学習データを構築し、Phi3とQwen-CoderをLoRAアダプタでファインチューニングする。さらに応答安定化として、強制結論プロンプト、二値分類ヘッド、対照分類ヘッドの3手法を導入した。
評価はPython-Java、Rust-Java、Rust-Python、Rust-Rubyの4ペアで行われ、蒸留によって小型モデルの信頼性が一貫して向上し、分布シフト下では予測性能も改善した。加えて、分類ヘッド版は生成ベース推論と比較して推論時間を大幅に削減しており、CI/CDのような低レイテンシ運用での利用価値が具体化している。結果として、推論指向の蒸留と応答安定化の組み合わせが、コンパクトなオープンソースモデルをX-CCD用途で実用段階に引き上げたことが示された。