UAEのTechnology Innovation Institute(TII)が2026年4月21日にHugging Face上で公開したQIMMA(قِمّة、アラビア語で『頂上』の意)は、アラビア語LLMのリーダーボードとして初めて『評価データ自体の品質』に正面から取り組んだ統合プラットフォームである。
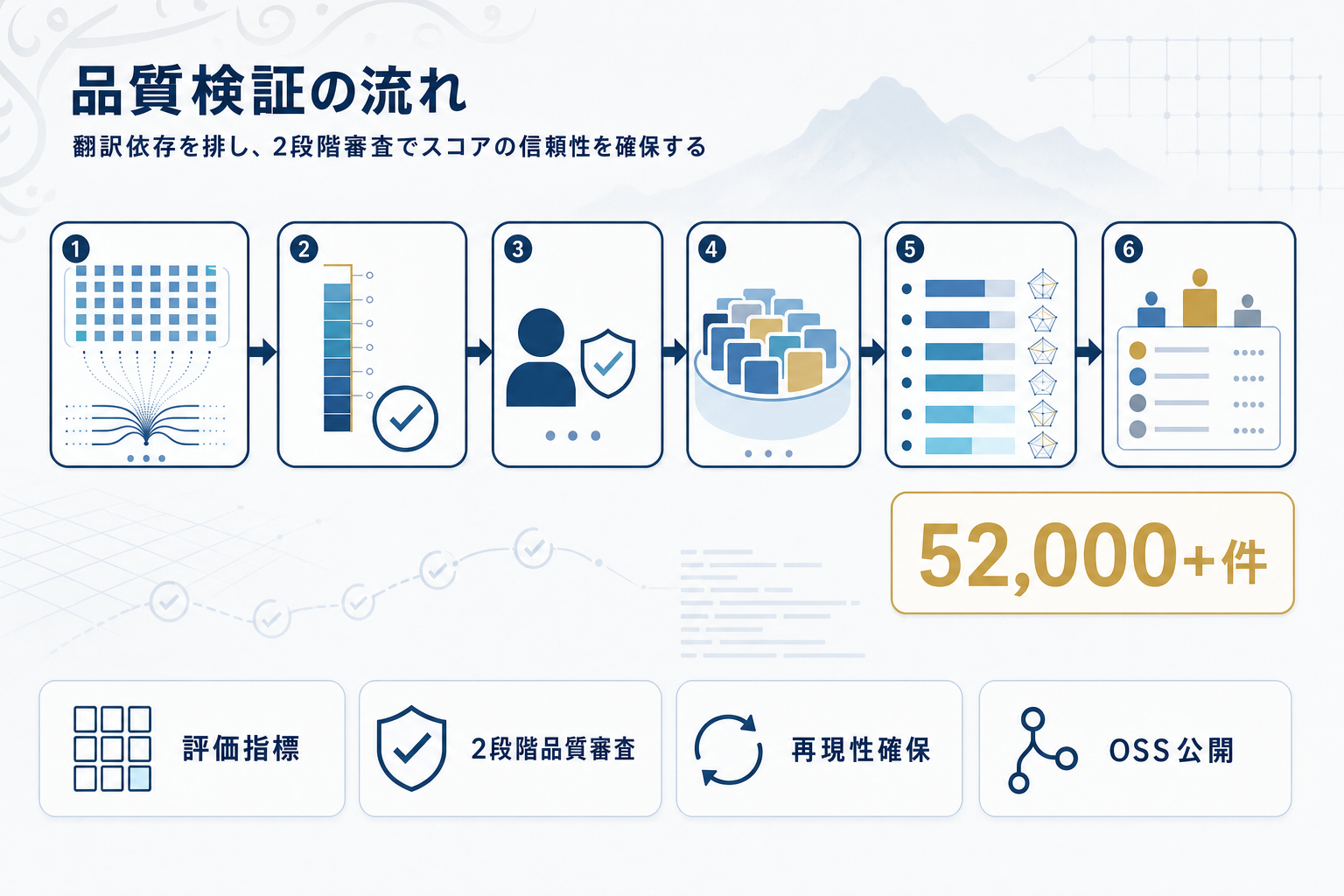
対象は14ベンチマーク・109サブセット・52,000件超のサンプルにおよび、文化・STEM・法律・医療・安全・詩文学・コーディングの7ドメインをカバーする。中核となる品質検証パイプラインは2段構成で、Stage 1ではQwen3-235B-A22B-InstructとDeepSeek-V3-671Bによる10点ルーブリック自動評価を行い、Stage 2でネイティブ話者が人手レビューを実施する。
この検証により、ArabicMMLUで3.1%(436件)、MizanQAで2.3%(41件)といった系統的な品質問題が発見された。さらにコードベンチマークでは3LM HumanEval+の88%、3LM MBPP+の81%のプロンプトが修正され、アラビア語リーダーボードとして初めてコーディング評価が統合された。
評価フレームワークにはLightEval・EvalPlus・FannOrFlopが採用され、サンプル単位の推論出力が公開されるため、モデル間のスコア差をプロンプト単位で切り分けて検証できる。これはベンチマークのブラックボックス化に対する明確なアンチテーゼであり、日本語を含む他の非英語言語のベンチマーク設計にも転用可能な方法論として参照価値が高い。