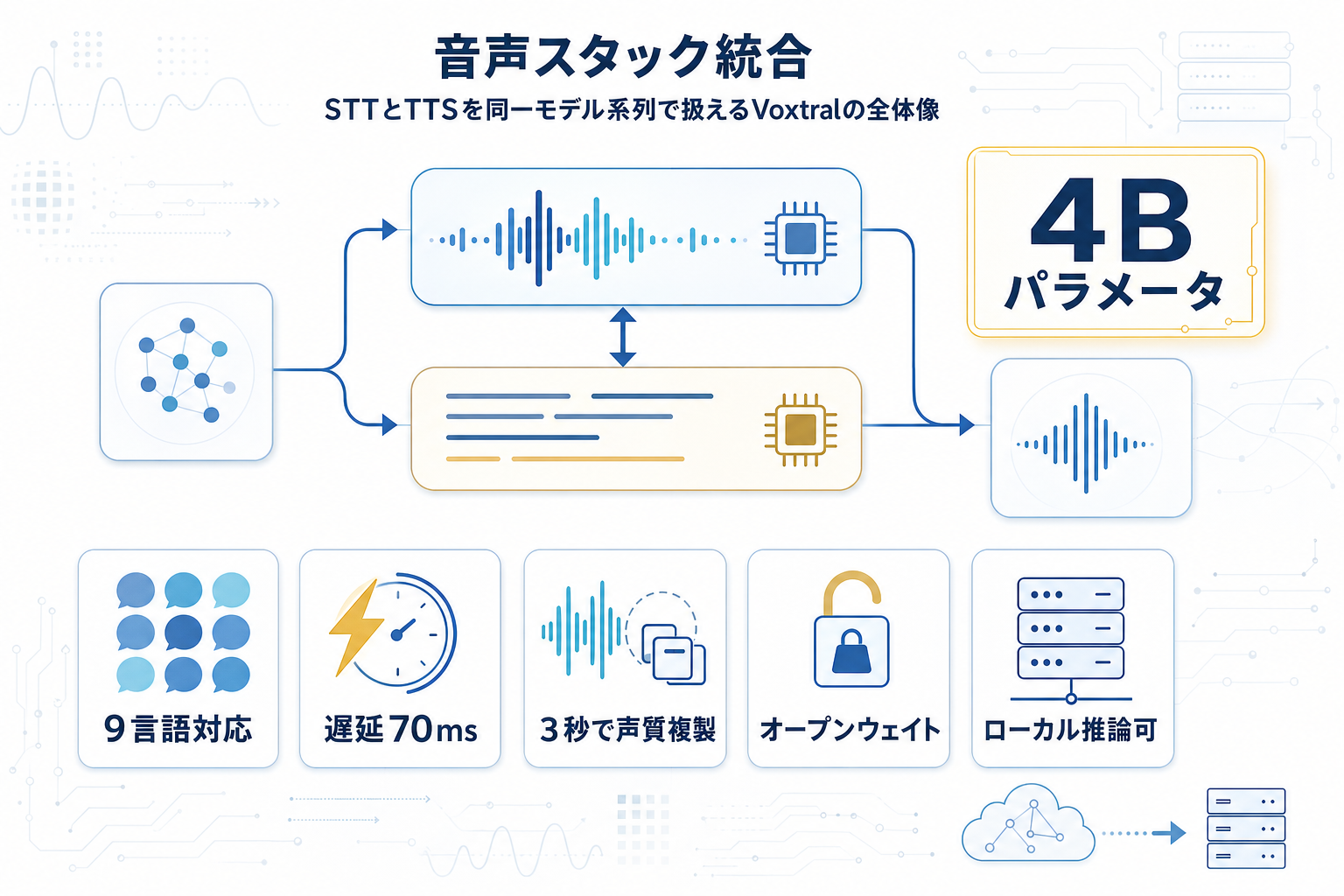
Mistralが公式ブログ「Speaking of Voxtral」で、音声合成モデル「Voxtral-4B-TTS-2603」とVoxtral Transcribeの公開を告知した。Voxtralはこれまで音声認識モデルとして先行展開されてきたが、今回のTTS追加により、音声入力(STT)と音声出力(TTS)を同一系列のモデルで扱える音声スタックへ拡張された。
注目すべきは配布形態である。Voxtral-4B-TTS-2603はHugging Face上で重みが公開されており、APIを介さずに自社インフラで推論・ファインチューニングが可能になる。これはElevenLabsやOpenAIのTTSといったクローズドAPI中心の主要プレイヤーに対し、オープンウェイト側からの選択肢を提示するものだ。
日本の開発現場にとっての意味は2つある。第一に、音声エージェントやコールセンター向けアプリケーションを構築する際、STTとTTSをMistral単一ベンダーのモデルで揃えられ、統合と運用の複雑さが下がる。第二に、データを外部APIに送らずに済むため、個人情報や商談音声を扱うユースケースで導入ハードルが下がる。
一方、TTSのオープンウェイト配布は音声クローンの悪用リスクを伴う領域である。ライセンス条項と利用ガイドラインを実装前に確認することが必須となる。日本語品質、推論コスト、レイテンシは公表資料だけでは判断できないため、実機での比較検証が次のステップになる。