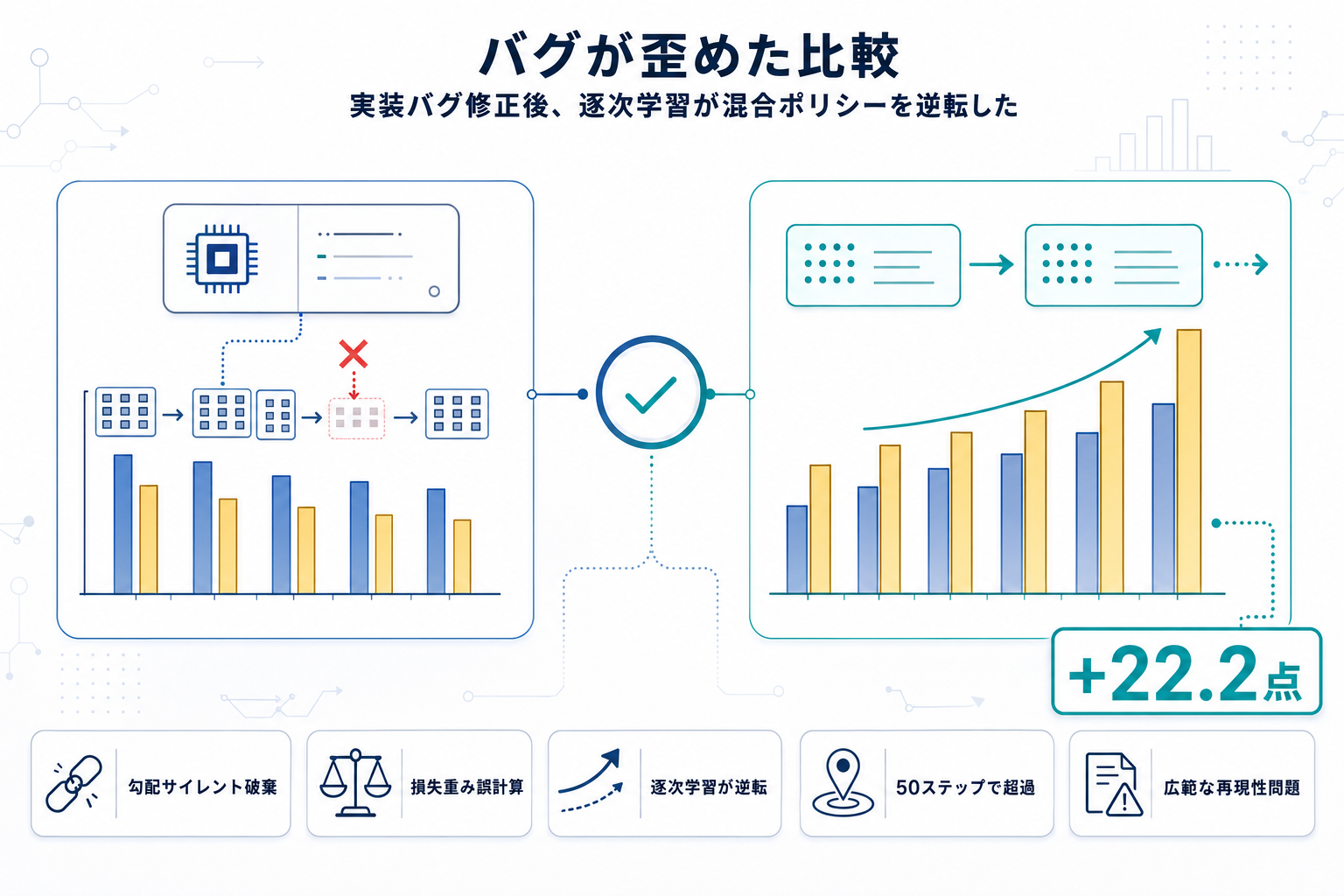
2026年4月26日にarXivで公開された本論文は、近年盛んに提案されてきた「混合ポリシー最適化」手法の優位性主張の根拠を揺さぶる内容である。著者らは、比較対象となってきた標準SFT-then-RLパイプラインのベースラインが、2つの独立した実装バグにより不当に低いスコアに抑え込まれていたと指摘する。
第一のバグはDeepSpeedのCPUオフロードオプティマイザに存在し、勾配累積中に中間マイクロバッチをサイレントに破棄する。このコードパスはTRL、OpenRLHF、Llama-FactoryといったLLMファインチューニングの主要フレームワークから利用されており、影響範囲は広い。第二のバグはOpenRLHF固有で、ミニバッチ毎の損失の重み付けを誤って集約する。著者らによれば、性能差の大部分はオプティマイザ側のバグが説明し、損失集約バグは補助的に寄与する。
両バグを修正したうえで再評価すると、標準SFT-then-RLはQwen2.5-Math-7Bで+3.8点、Llama-3.1-8Bで+22.2点、評価したすべての既発表混合ポリシー手法を上回った。さらにRLステップをわずか50回に切り詰めた短縮版でさえ、より少ないFLOPsで混合ポリシー手法を上回ると報告されている。
実務面での含意は明確だ。TRL・OpenRLHF・Llama-Factoryを用いて行われた過去のSFT結果は、学習ログが正常に見えていても実効的な更新が欠落していた可能性がある。独自RL手法を内製・採用する前に、まず修正済みの標準パイプラインを同条件で走らせ直し、改善幅の再定義を行うことが必要となる。