本研究は、検証可能報酬による強化学習(RLVR)で推論モデルをポストトレーニングする際、初期成功確率p_0が小さいと学習が停滞する「コールドスタート問題」を、Tsallis q-対数という単一の数学的道具で解決する枠組みを提示した。
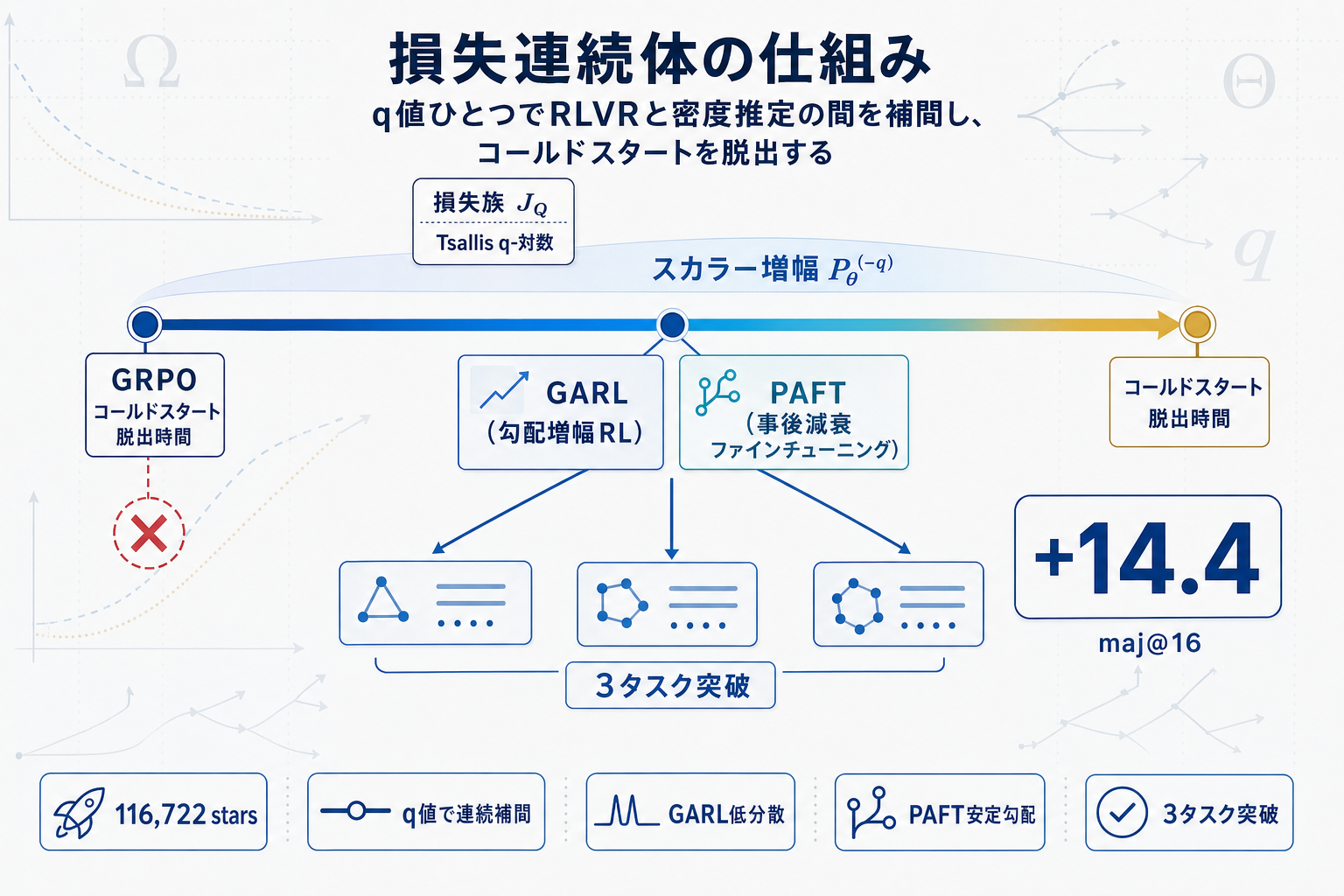
損失族J_Qは、q=0で従来のRLVR(搾取極)、q=1で潜在軌跡の対数周辺尤度(密度推定極)に対応し、その間を連続的に補間する。重要なのは、全メンバーが同じ勾配方向を共有し、差はスカラー増幅P_θ^(-q)のみという点である。この増幅が学習率とは独立に各事例を再重み付けすることで、コールドスタート脱出時間が搾取極のΩ(1/p_0)から密度推定極のΘ(log(1/p_0))へと指数的に短縮される。
実装側では、P_θが扱いづらいため2つのモンテカルロ推定器が導出されている。GARL(Gradient-Amplified RL)は事前分布からサンプリングしRL勾配を増幅する方式で分散が低い。PAFT(Posterior-Attenuated Fine-Tuning)は事後分布から重要度リサンプリングしSFTを走らせる方式で、意味的に一貫した勾配を持つ。両者ともバイアスはO(q/(M・P_θ^(q+1)))に抑えられる。
実験はFinQA、HotPotQA、MuSiQueの3タスクで実施され、q=0.75のGARLがGRPOが完全失敗するコールドスタート条件で学習進行に成功した。warm startでは、訓練が安定するFinQAで低qのGARLが優位、HotPotQAとMuSiQueではGARLが不安定化する一方でq=0.75のPAFTが安定した勾配を提供し、HotPotQAで最良のmaj@16=47.9(GRPO比+14.4)を記録している。