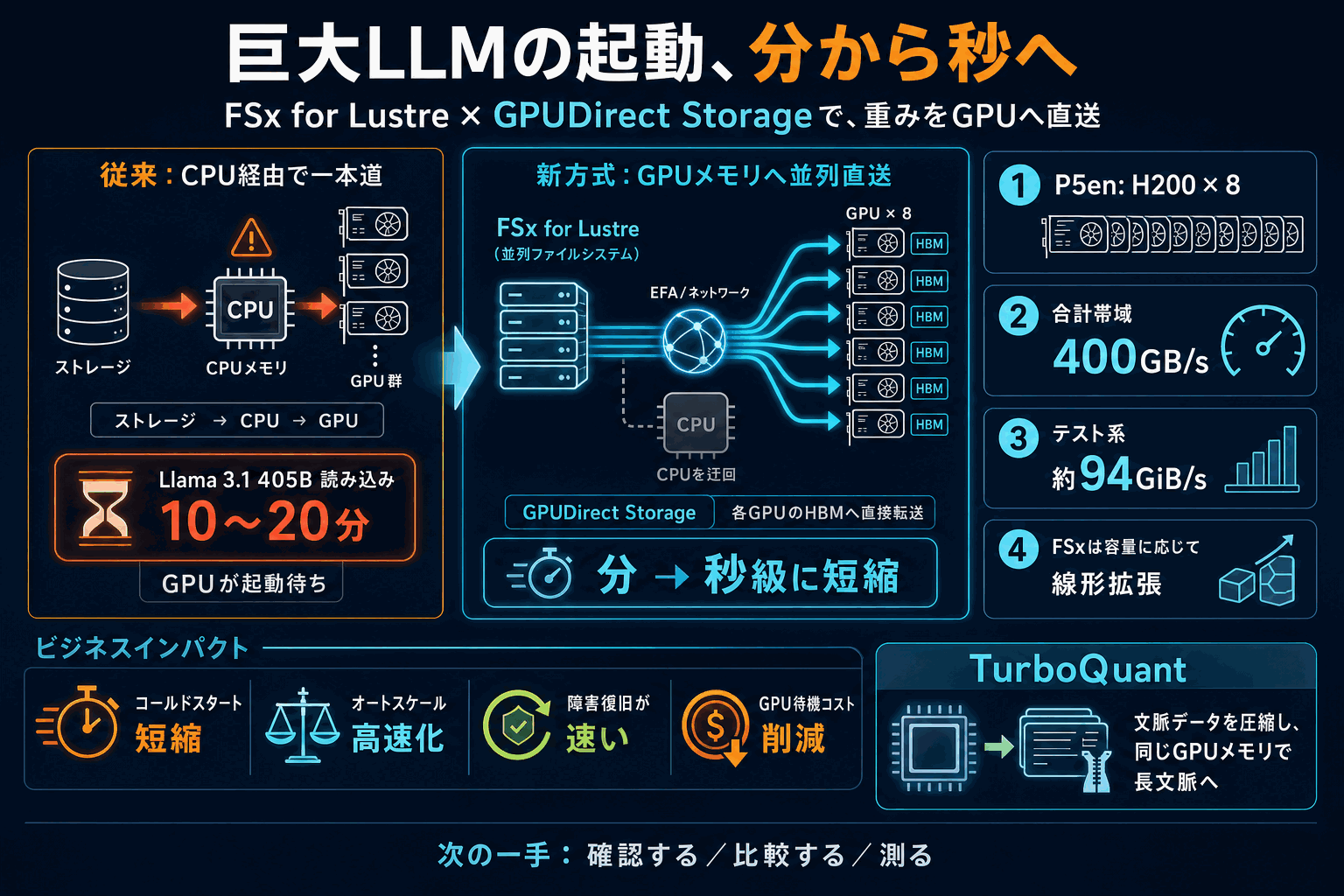
AWSがAmazon FSx for LustreとNVIDIAのGPUDirect Storageを組み合わせ、CPUを経由せずストレージから各GPUのメモリ(HBM)へモデルの重みを直接並列転送する手法を公開した。従来方式ではLlama 3.1 405Bの読み込みに10〜20分かかり、この間に高価なGPUが起動待ちで遊んでいた。
P5en(NVIDIA H200×8基)は16本のネットワーク接続で合計400GB/秒の帯域を持ち、うち8本以上を直接転送に使える。テスト構成のファイルシステムは約94GiB/秒のスループットを出し、容量に応じて線形に拡張できる。読み込み短縮は新規インスタンスの即応性、オートスケールの反応速度、障害復旧の速さ、GPU稼働効率に直結する。
あわせて、文脈データを圧縮して扱える文章量を拡大するTurboQuantも紹介された。読み込み速度と長文脈の両面で、巨大モデル運用の応答遅延とコストに効く実務的な改善である。