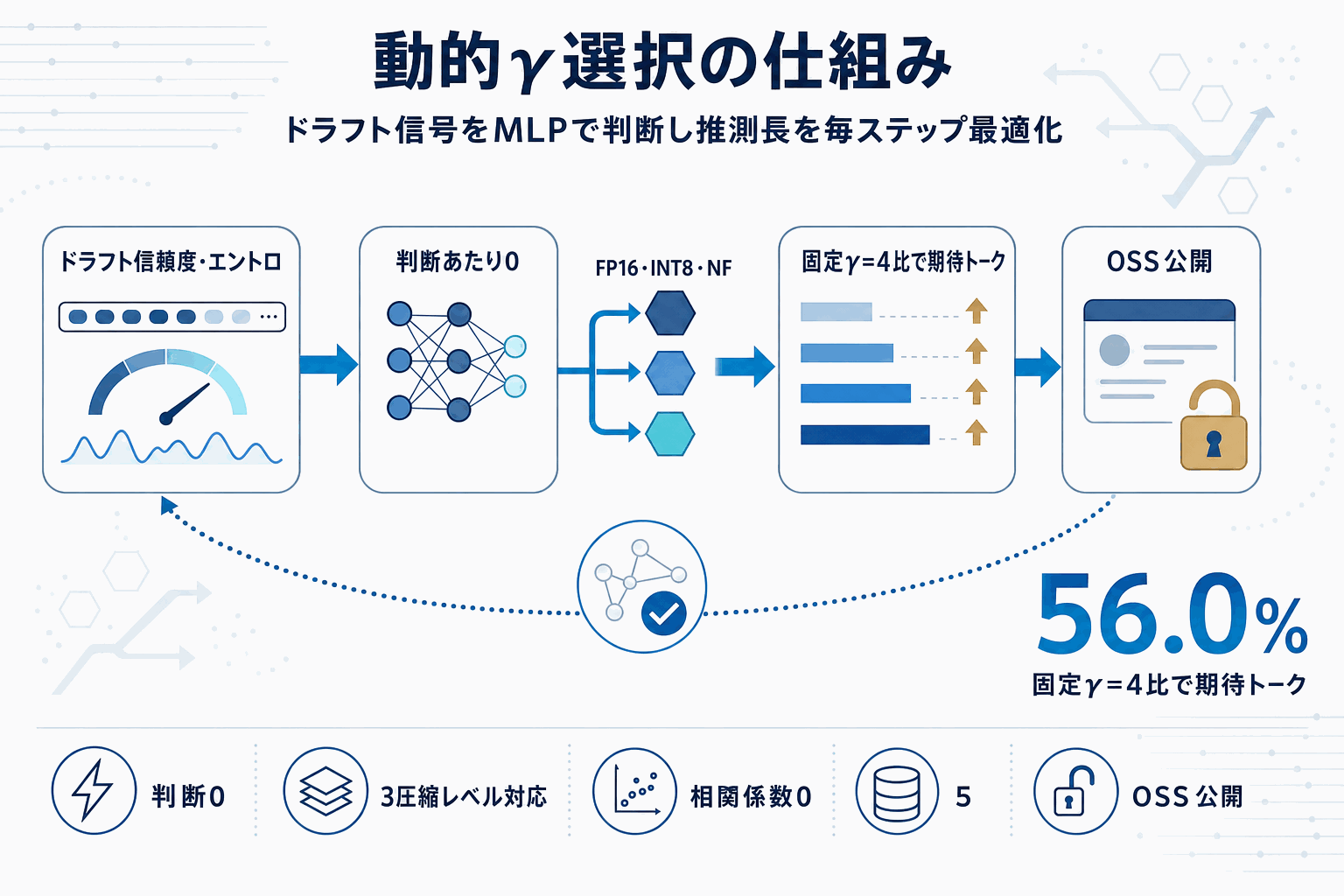
SpecKVは、大規模言語モデル(LLM)の推論を加速する投機的デコードにおいて、1ステップあたりのドラフト提案数である推測長γを動的に選ぶ軽量コントローラである。既存のほぼ全ての実装はγ=4など固定値を用いてきたが、著者らは4種のタスクカテゴリ、4種のγ、3種の圧縮レベル(FP16・INT8・NF4)にわたり合計5,112ステップの記録を収集し、ステップごとの承認率・ドラフトエントロピー・ドラフト信頼度を分析した。
分析の結果、最適なγは圧縮レジームによってシフトし、ドラフトモデルの信頼度とエントロピーは承認率と約0.56の相関を持つことが確認された。この2信号を入力とする小型MLPをステップごとに走らせ、期待トークン数を最大化するγを選択する設計が採用されている。判断あたりのオーバーヘッドは0.34msで、ステップ時間の0.5%未満に抑えられている。
性能面では、固定γ=4のベースラインに対し期待トークン数が56.0%改善し、ペアブートストラップ検定でp<0.001の統計的有意差が示された。INT8・NF4といった量子化形式での本番運用が広がる局面で、圧縮レベルに応じて推測長を合わせるという視点は、固定値運用を前提としたチューニングを見直す材料になる。
実装面での重要な点は、プロファイリングデータ・学習済みモデル・ノートブックが全てオープンソースとして公開されていることである。これにより、自社のドラフト/ターゲットモデル組で承認率とドラフト信号の相関を測り直し、動的γ選択が自環境で機能するかを切り分ける検証が、比較的低コストで実行できる。