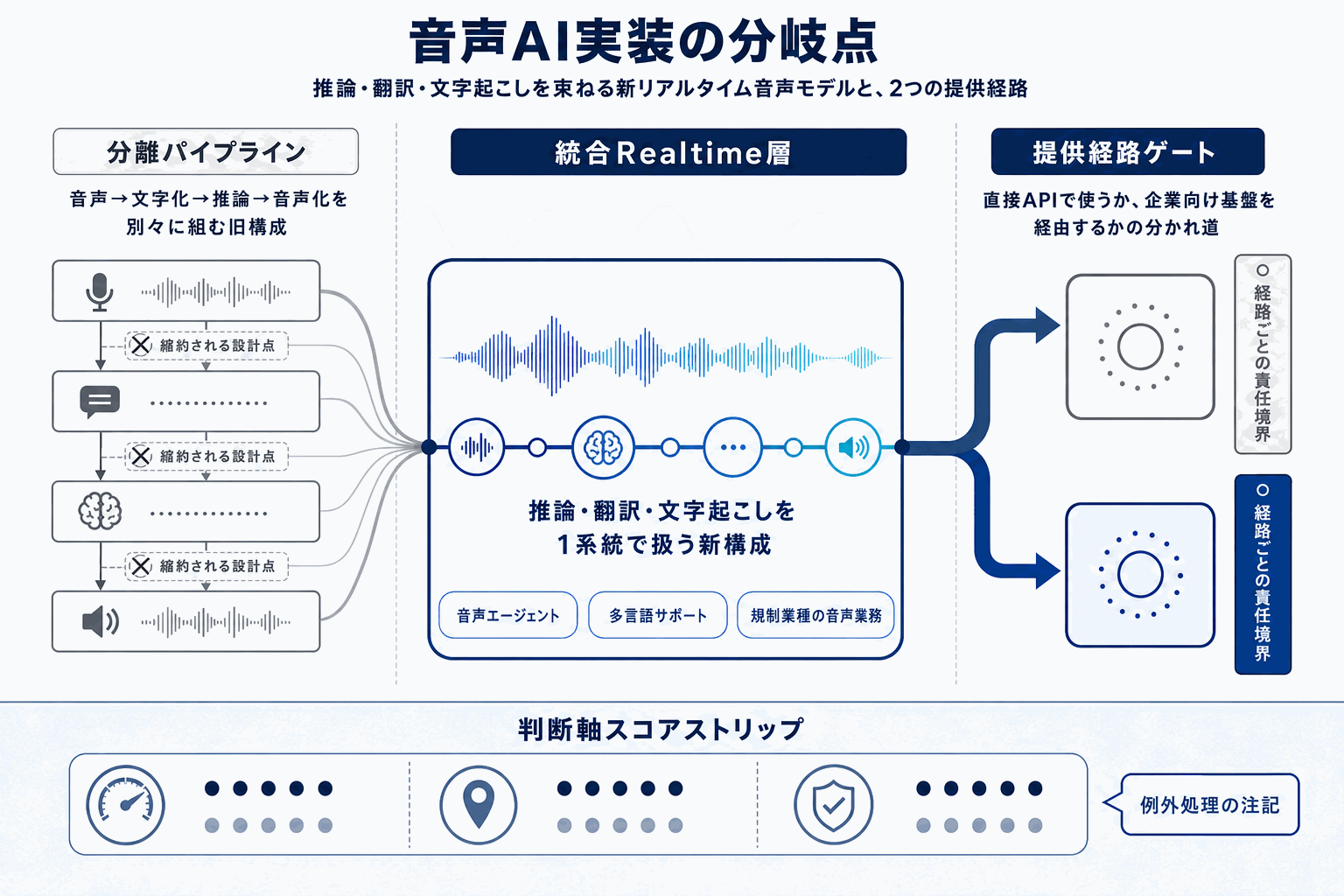
OpenAIは2026年5月7日、APIに新しいリアルタイム音声モデル群を追加したと発表した。これらのモデルは推論、翻訳、音声文字起こしに対応し、より自然でインテリジェントな音声体験の構築を目的としている。
注目すべきは、音声入出力と推論・翻訳・文字起こしが同一のAPIレイヤで扱える構成だ。従来はSTT(音声認識)、LLM(推論)、TTS(音声合成)を別々に組み合わせてパイプラインを作る必要があり、遅延や状態同期、割り込み処理が実装上の難所だった。新モデル群はRealtime API上で提供され、音声エージェントの中核機能が一つの経路で揃う。
日本の開発現場にとっての意味は大きく二つある。第一に、カスタマーサポートや音声UI、アクセシビリティ対応といった領域で、既存ベンダーの構成と新モデル構成を同じ業務タスクで比較できる状態になったこと。第二に、Azure AI Foundryでも関連ドキュメントが整備されており、規制業種や大企業がエンタープライズ要件を満たしながら導入する経路が明確になったことだ。
一方で、音声データはPII(個人識別情報)や会話内容を含むため、OpenAI API直接利用とAzure経由のどちらでデータを扱うかは、実装前に切り分けが必要になる。金融・医療・行政など、データ所在と監査ログ要件が厳しい業種では特に重要な設計判断となる。
読者が今日取れる一手は、自社の音声ユースケースで現行構成と新モデル構成を応答遅延・文字起こし精度・コストの3軸で比較する準備を始めることだ。既にRealtime APIを使っている場合は、新モデルへの移行評価が次のステップとなる。