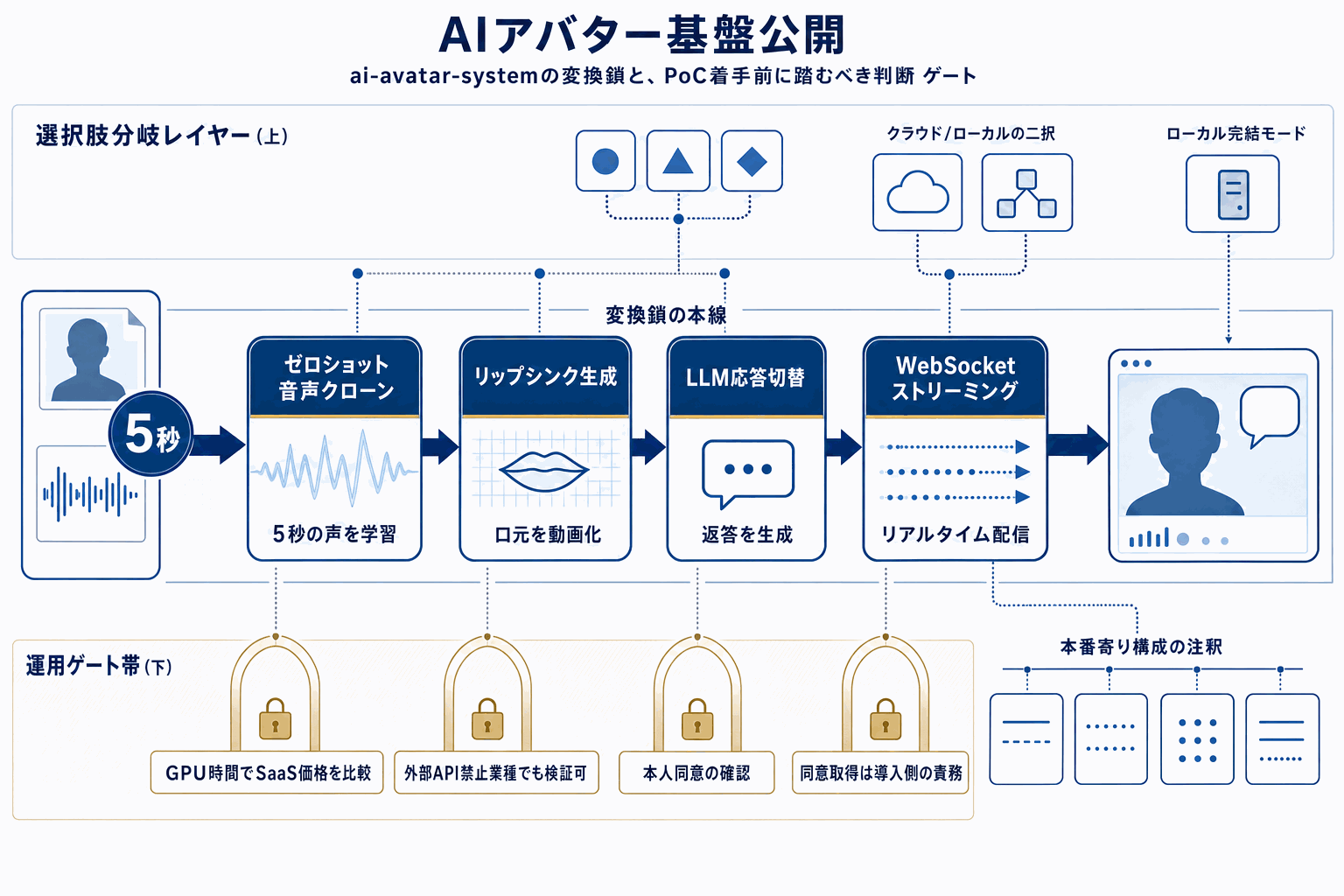
「ai-avatar-system」は、写真1枚と短い音声サンプルから、任意の顔・声で会話できるアバターをリアルタイムに動かすためのオープンソース基盤である。音声合成にはXTTS v2を採用し、5秒程度のクリップから18言語以上でゼロショットの音声クローンを行う。口元の生成にはMuseTalk V1.5を使い、V100クラスのGPU上で256×256・30FPSのリップシンク動画を生成する。応答生成のLLMはClaude、GPT-4o、ローカル実行のLlama 3(Ollama)を設定で切り替える構成で、音声認識にはWhisperが組み込まれている。
運用面では、AWS g5.xlarge(A10G GPU)へのワンコマンドデプロイスクリプトが同梱され、float16推論で約2倍の高速化を行う前提が示されている。スポット利用で約$0.30/時という具体的なコスト目安があるため、自社ホスティングとクローズドなアバターSaaSの費用を同じ土俵で比較しやすい。USE_LOCAL_STORAGE=trueにすればAWS非依存のローカル開発モードでも動くため、外部クラウドに素材を置けない業種でも手元検証から始められる。
本番寄りの周辺要素としてJWT認証、Celeryによる非同期処理、Prometheus監視、Terraformによるインフラ定義が含まれる点は、個人のデモではなくチームでのPoC着手を想定した構成といえる。一方で、写真と5秒の音声だけで本人らしい顔・声を再現できる以上、同意取得、なりすまし対策、生体情報の取り扱いは導入側の設計責任になる。技術的な参照価値は高いが、商用転用時には利用規約、各モデルのライセンス、対象者の同意フローを先に詰めることが、実装着手時の最大の落とし穴になりやすい。