AWS Machine Learning Blogは2026年5月1日、Amazon Novaモデルを対象にLLM-as-a-judge(RLAIF)による強化ファインチューニングの実装指針を公開した。静的な報酬関数では捉えにくいトーン・安全性・関連性といった文脈依存のニュアンスを、別のLLMに採点させて報酬信号に変換するアプローチだ。
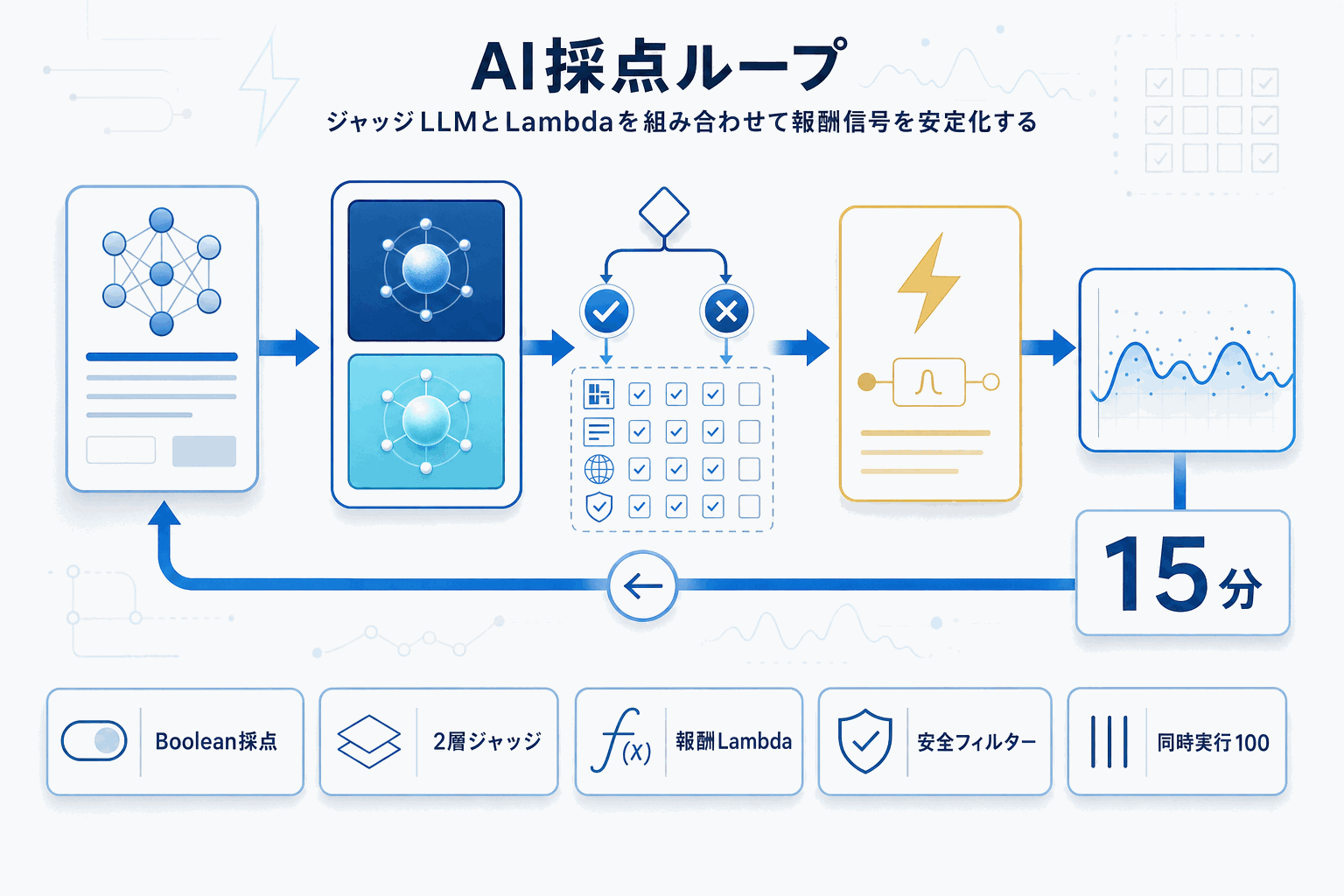
記事ではジャッジ方式をRubric-based(ルーブリック採点)とPreference-based(比較選好)の2種類に整理し、採点の安定性を重視する場合はBoolean(合否)スコアリングを推奨している。1-10段階採点よりも判定分散が小さく、学習ループ内での報酬SN比が改善するためだ。ジャッジモデルの例として、高精度用途にAmazon Nova Pro・Claude Opus・Claude Sonnet、コスト重視用途にAmazon Nova 2 Lite・Claude Haikuが挙げられている。
報酬関数はジャッジ出力だけでなく、Lambda関数による決定論的コンポーネント—フォーマット検証、長さペナルティ、言語一貫性チェック、安全フィルター—と組み合わせる設計が推奨される。Lambdaのタイムアウトは15分、プロビジョニング済み同時実行数は約100という具体的な運用値も示され、PoCから本番運用への接続点が明確になった。
AWS利用の日本企業にとっては、外部RLHFベンダーを介さずにBedrock/Nova上で自社データによるアライメント調整に着手できる意味が大きい。ただし単純に手順をなぞるだけでは落とし穴がある。ジャッジLLMのバイアスが報酬に転写されるリスク、採点コストが学習コスト全体を押し上げる点、Boolean Rubricの設計品質が成果を左右する点は、実装者が自分で切り分けて測る必要がある領域だ。