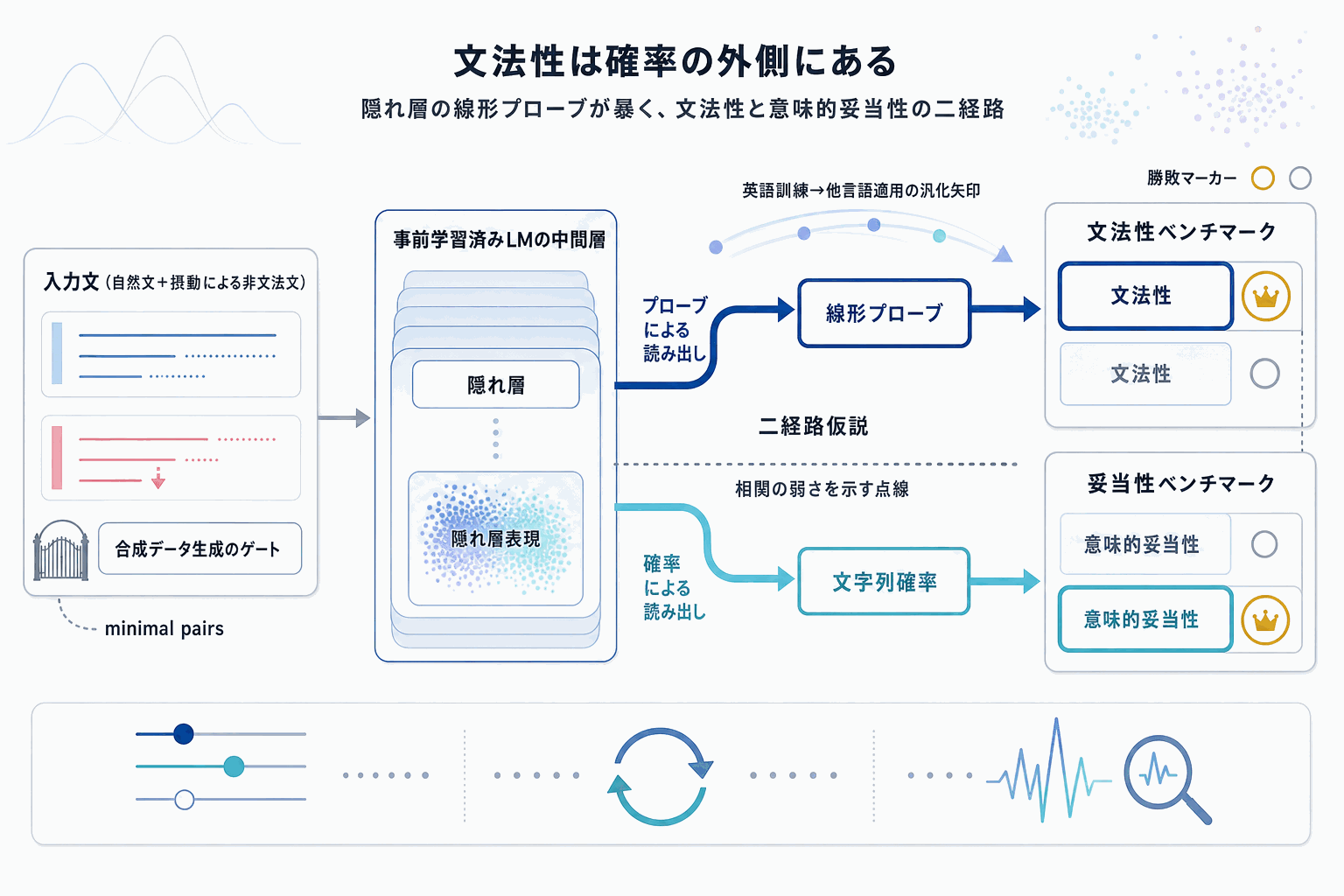
この研究は、事前学習済み言語モデル(LM)が「文法的な文」と「非文法的な文」をどう区別しているかという基本的な問いに、新しい角度から答えを出した。
従来、LMの文法性判断能力はminimal pairs(文法的な文とわずかに崩した文のペア)での文字列確率比較で測られてきた。しかし、コーパス全体で見ると文字列確率は文法性を鋭く区別しない。そこで著者らは、自然テキストに摂動を加えて合成した非文法文データセットで線形プローブを訓練し、LMの隠れ層が文法性に関する情報を独立に保持しているかを検証した。
結果は3点で注目される。第一に、この単純な線形プローブが人手でキュレートされた文法性ベンチマークに汎化し、文字列確率ベースの判定を上回った。第二に、英語で訓練したプローブが複数の他言語の文法性ベンチマークでも文字列確率を上回り、非自明な言語横断汎化を示した。第三に、両者が文法的で妥当性のみ異なるminimal pairs(意味的妥当性ベンチマーク)では、プローブは文字列確率より劣った。
この非対称性は重要で、文法性と意味的妥当性がLM内部で別々のメカニズムに支えられていることを示唆する。プローブスコアと文字列確率の相関が弱い点も、両者が独立した情報を捉えている裏付けになる。
実装観点では、LM評価や品質モニタリングを設計する際に、文字列確率だけでなく中間層プローブを併用する選択肢が具体化される。多言語対応の観点でも、英語訓練プローブの再利用性は低リソース言語での評価設計にとって実用的な示唆を持つ。