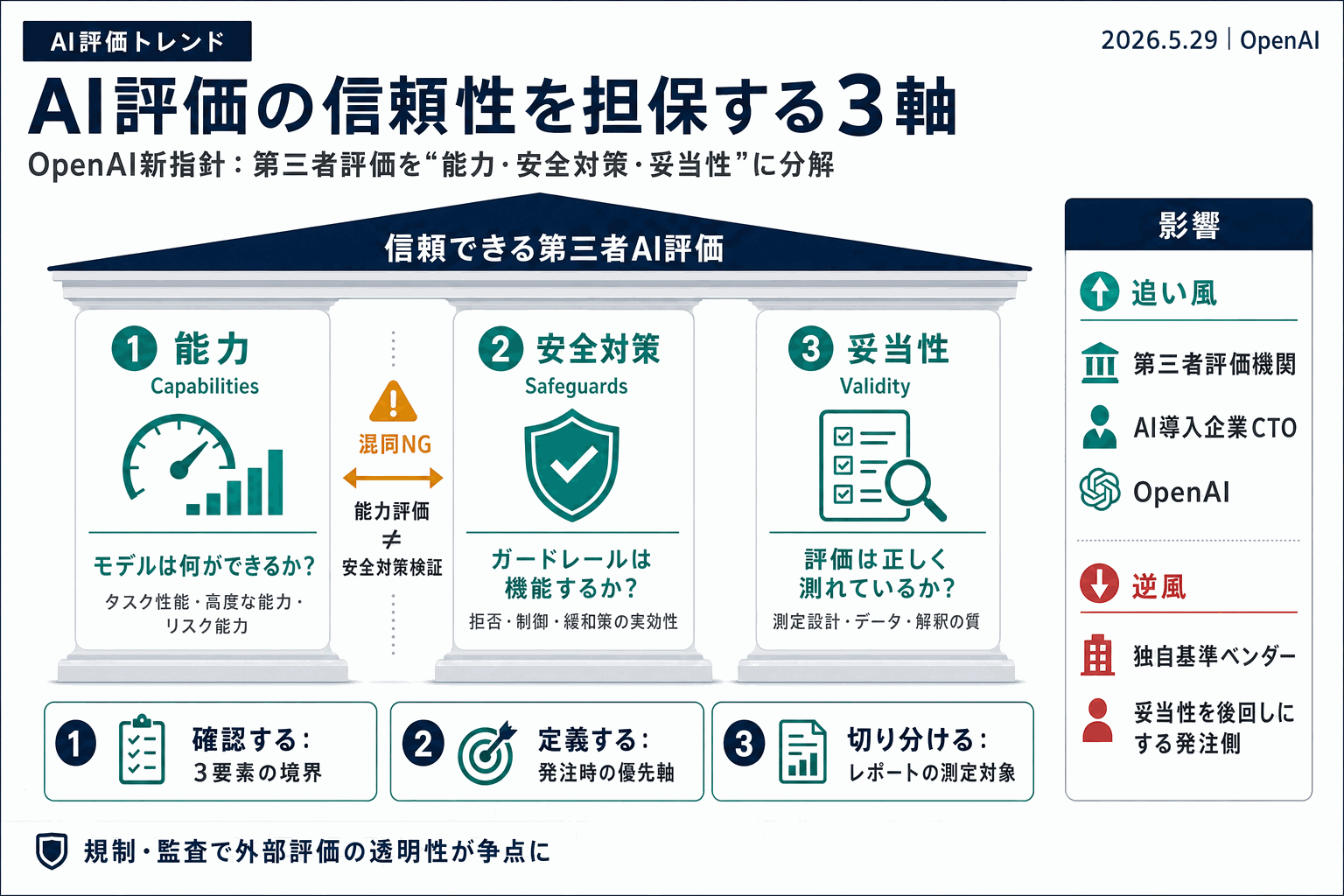
OpenAIが2026年5月29日、第三者によるAIモデル評価の進め方に関するガイダンスを公開した。フロンティアシステムを対象に、モデルの能力(capabilities)・安全対策(safeguards)・評価の妥当性(validity)をどう測るかを扱っている。
能力評価と安全対策の検証は性質が異なる。前者はモデルが何をできるかを測り、後者はガードレールが機能するかを確かめる作業で、同じ手法で測ると結果が混線する。OpenAIはこの切り分けに加え、測定そのものが正しく測れているかという妥当性を3つ目の軸に据えた。
高性能なモデルが普及する中、開発元以外の独立した第三者が評価する必要性は高まっているが、方法論や信頼性を担保する共通枠組みは乏しかった。開発元自らが評価のプレイブックを示すこの動きは、第三者評価サービスの標準化の方向を読む手がかりになる。