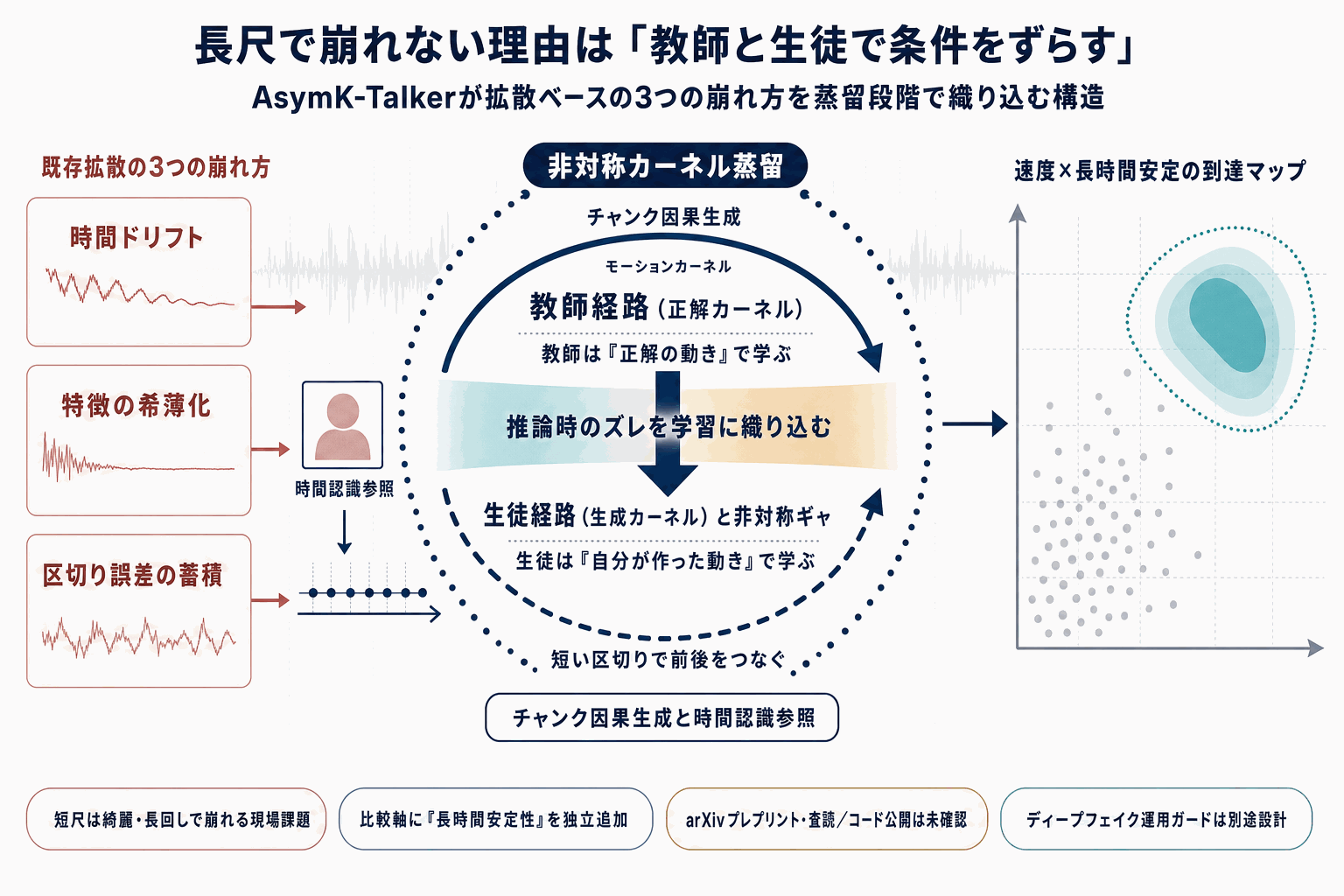
AsymK-Talkerは、音声から顔映像を生成する「トーキングヘッド」分野で、拡散モデルが抱えてきた3つの壁に同時に挑む手法として提案された。すなわち、リアルタイム推論を阻む因果的非効率、時系列的に一貫した条件付けとの非互換、そして長時間生成で画質や口元同期が徐々に劣化するドリフトである。
中核は3つの構成要素だ。KCLG(Kernel-Conditioned Loop Generation)は、モーションカーネルを条件としてチャンク単位に因果的生成を回し、前後フレームの一貫性を保つ。TRE(Temporal Reference Encoding)は、静的な本人画像を時間認識型の潜在に変換し、音声と映像の同期を高める。AKD(Asymmetric Kernel Distillation)は、教師モデルを正解モーションカーネルで学習させ、生徒モデルには自ら生成したカーネルから学ばせる非対称設計で、長尺でも破綻しにくい生徒を作る。
読者にとっての意味は明確である。アバター配信やビデオ会議、生成コンテンツ制作では「短尺のデモは綺麗だが、長回しで崩れる」ことが量産運用のボトルネックになってきた。AsymK-Talkerは、学習時点で推論時の条件分布ずれを織り込むことでこの課題に取り組んでおり、既存手法を評価する際に「長時間安定性」を独立した比較軸として扱う根拠になる。
一方で本稿はarXivプレプリントであり、学会査読、コード・重みの公開範囲、ライセンス、具体的な推論速度数値などは本ソース内では確認できない。自社プロダクトへの採用可否は、同一素材での既存手法との比較検証と、ディープフェイク悪用への運用上のガード設計をセットで進める必要がある。