ActCamは、動画生成における「演技(キャラクター動作)」と「カメラワーク(軌跡・パラメータ)」を同時に、かつ追加学習なしで制御することを狙った手法である。入力は参照動画とターゲットのカメラモーションで、フレーム間で幾何学的に整合するポーズと深度の条件を生成し、それを事前学習済みの画像→動画拡散モデルに流し込む。
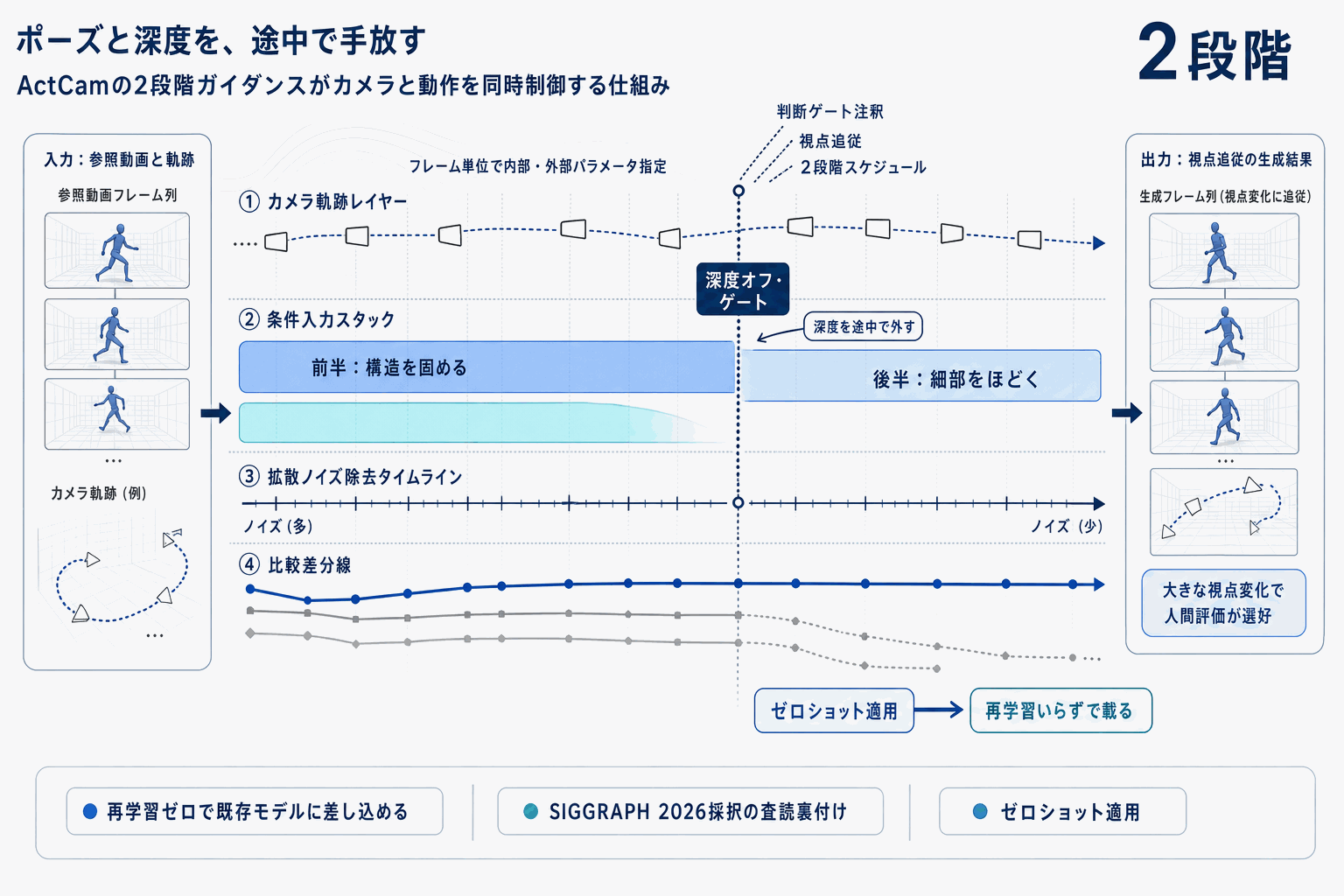
核となるのは2段階のコンディショニングスケジュールである。初期のノイズ除去ステップではポーズとスパースな深度の両方で条件付けし、シーン構造を強制する。後半では深度条件を外し、ポーズのみで高周波ディテールを精緻化する。深度を最後まで使い続けると生成が過剰に拘束され細部が潰れる一方、ポーズだけでは大きな視点変化でシーンが崩れる。この切替が両者の欠点を回避する鍵になっている。
評価では、多様なキャラクター動作と大きな視点変化を含む複数ベンチマークで、ポーズのみ制御や既存のポーズ+カメラ手法と比較され、カメラ追従性・モーション忠実度の両方で上回った。人間評価でも、特に大きな視点変化の条件下で選好されている。
実装判断として重要なのは、ActCamがdepth+pose条件に対応する任意の事前学習済み画像→動画拡散モデルに乗る点である。再学習コストやモデル差し替え時の再チューニングが不要で、映像制作・ゲーム・VFXのワークフローに組み込みやすい。SIGGRAPH 2026採択という査読の裏付けもあり、検証着手の優先度は上げやすい。