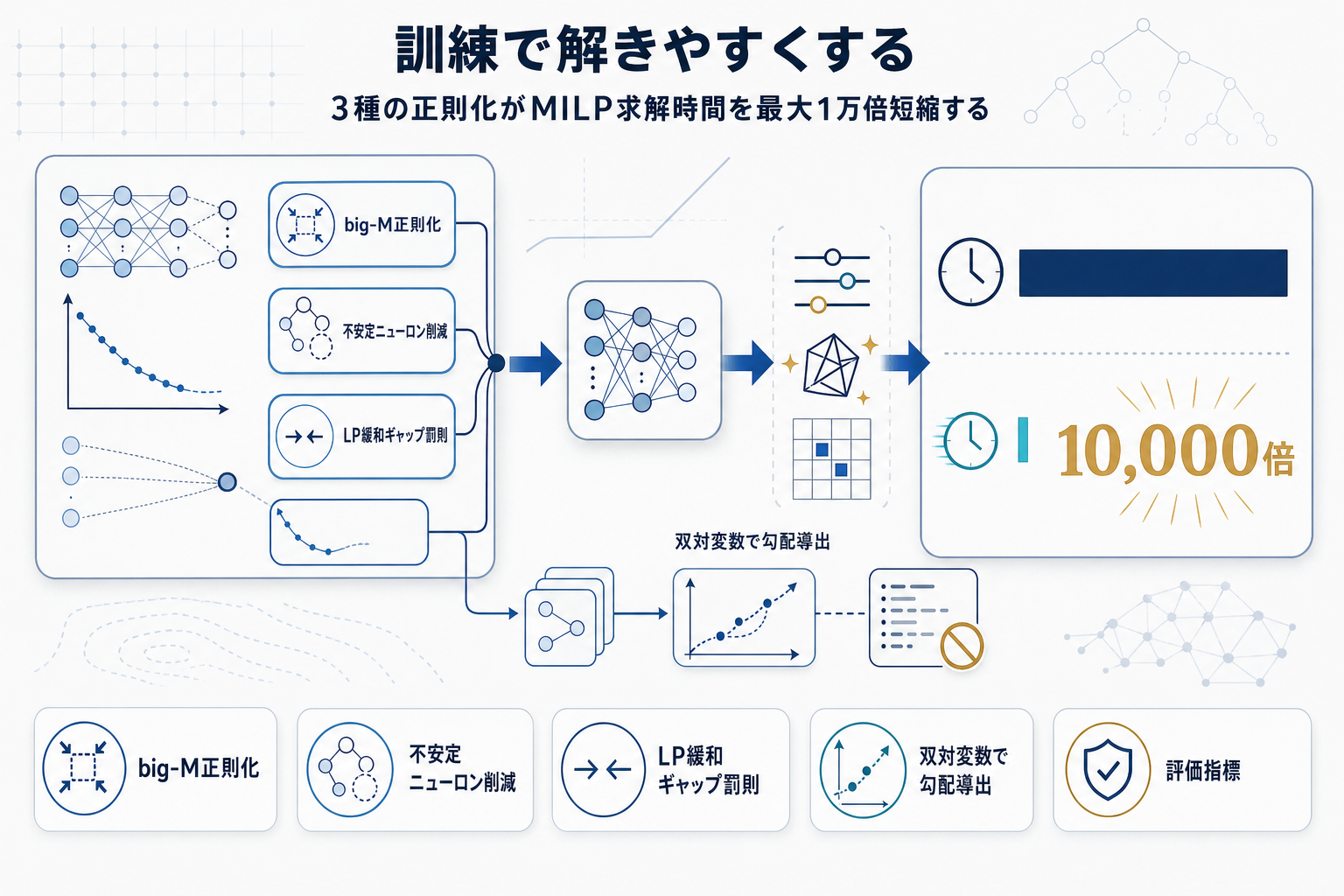
ReLUニューラルネットワークは区分線形関数として厳密にMILP(混合整数線形計画)に埋め込めるため、学習した関数上で大域最適化を行う用途に使われてきた。化学プロセス設計、エネルギー需給計画、物流最適化など、ブラックボックスの物理・コストモデルを代理モデルで置き換え、最適化問題に組み込む実務は広がっている。ただし、埋め込んだMILPの求解時間はネットワークの構造特性、すなわち二値変数の数とLP緩和の緊密さに依存し、これらは訓練時に決まるにもかかわらず、標準的な訓練目的関数には直接制御する仕組みがなかった。
本研究は訓練正則化項としてbig-M定数ペナルティ、不安定ニューロン数ペナルティ、そしてLP緩和ギャップペナルティの3種を提案する。特にLP緩和ギャップ正則化は、訓練サンプル点における連続緩和の差分をサンプル単位で罰則化するもので、その勾配がLP双対変数から導出できるためカスタム自動微分ツールを必要としない点が実装上の利点となる。これらを組み合わせることで、LPギャップのネットワークパラメータに関する全微分を近似でき、直接的・間接的な感度の双方を捉える。
実験では非凸ベンチマーク関数、および分位点ニューラルネットワーク代理モデルを用いた二段階確率計画問題において、正則化なしのベースラインに対してMILP求解時間を最大4桁(約1万倍)短縮しつつ、代理モデルの予測精度は同等水準を維持することが示された。産業応用で「解けない規模だった問題が解ける」水準の変化であり、代理モデル+最適化というパラダイム全体の実用範囲を広げる成果と位置付けられる。