対照学習(Contrastive Learning)はアノテーションコストを下げる自己教師あり学習の中核技術だが、大規模な自社データ構築が困難なため、第三者やインターネット由来のデータへの依存が常態化している。この構造が、データ提供者側の知的財産保護を難しくしてきた。
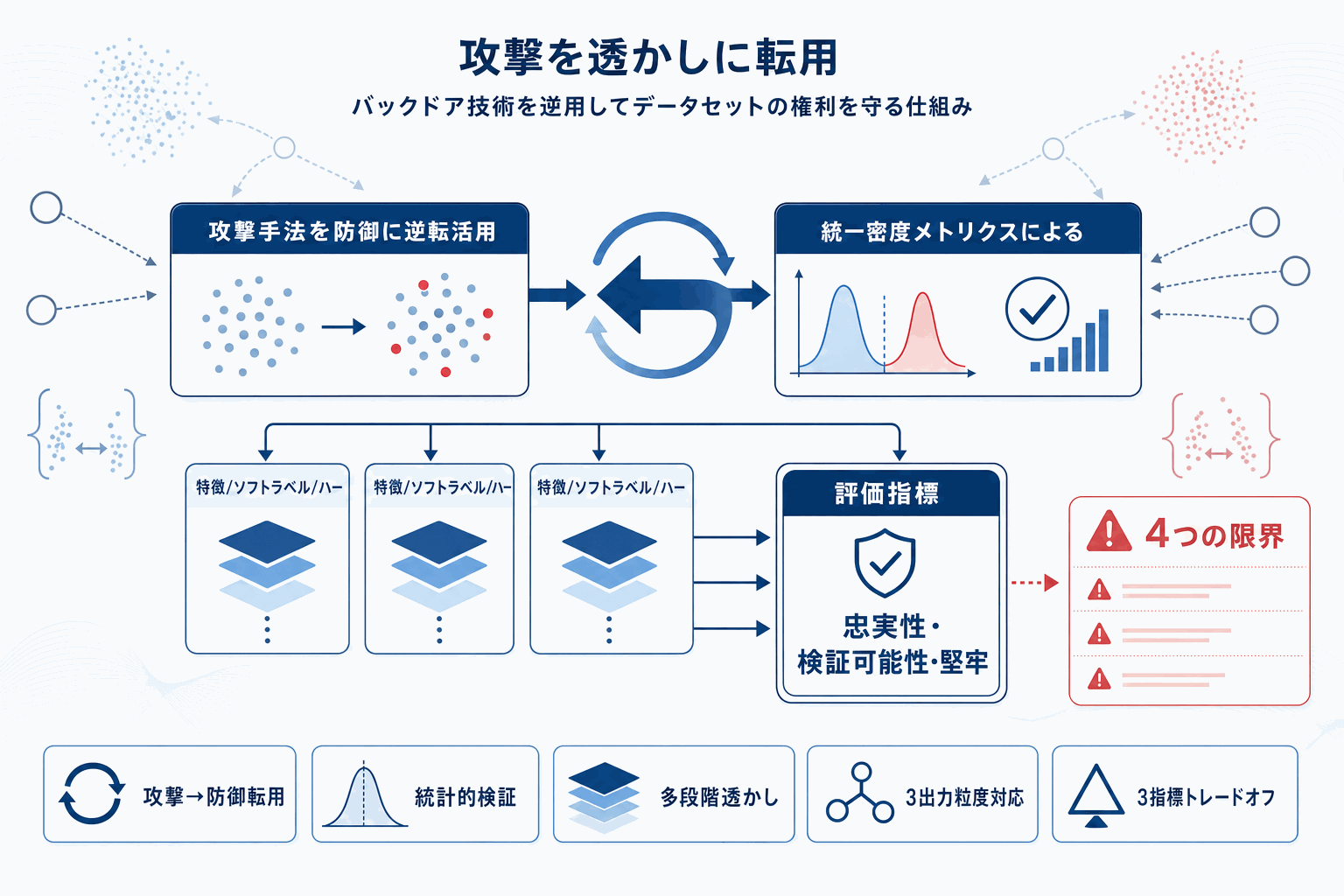
本論文は、対照学習向けに提案されてきたデータポイズニング型バックドア攻撃を体系的に評価し、既存手法には「データセット適応性の低さ」「攻撃成功率の低さ」「移植性の制限」「下流タスクの事前知識を要する前提」という4つの限界があることを示した。通常これらは攻撃側にとっての弱点だが、著者らはトリガーサンプルがクリーンサンプルと統計的に区別可能な乖離を示す点に着目し、これを電子透かしとして再解釈した。
直接的な転用は成功率の低さから困難だが、統一密度メトリクスによる統計的検証で補い、対照学習の出力形態に合わせて特徴レベル・ソフトラベル・ハードラベルの3段階に対応する透かしスキームを構築している。実験では一部のバックドア攻撃が、忠実性・検証可能性・堅牢性のトレードオフのもとで実効的な透かしとして機能することが示された。
日本の実務への含意は、データ提供契約とAI学習倫理ガイドラインの交点にある。学習データの無断利用を巡る議論が続くなか、事後に技術的検証が可能な仕組みは、契約履行確認の選択肢として位置づけが変わる。一方で、意図的にデータへシグナルを埋め込む行為の受容性はまだ整理されておらず、提供側と受領側の事前合意設計が前提となる。