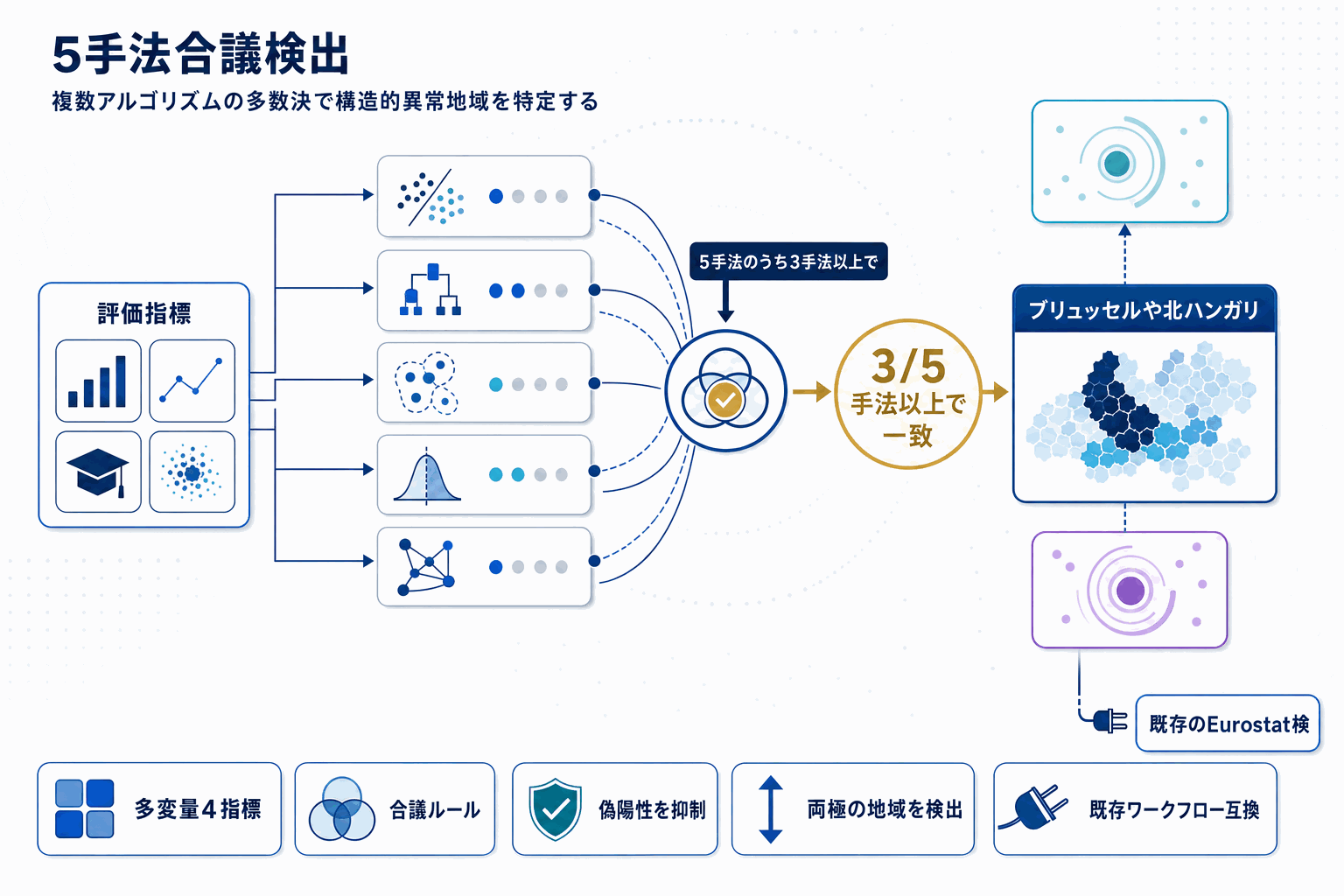
本論文は、欧州の地域統計(Eurostat の NUTS2 単位、2022年)に対して、教師なし機械学習で『構造的に異常な地域』を特定する枠組みを提案している。扱う指標は GDP per capita(PPS)、失業率、高等教育達成率、人口密度の4つで、これらを多変量プロファイルとして扱う点が従来の単変量検証との違いになる。
手法面では、単変量zスコア、マハラノビス距離、Isolation Forest、Local Outlier Factor、One-Class SVM の5つを並列に走らせ、『3手法以上で異常と判定された地域』のみを構造的異常として分類する合議ルールを採用する。単一アルゴリズムに依存すると手法固有の偽陽性が混入するため、複数手法の一致で堅牢性を確保する設計意図が読み取れる。
検出結果には、ブリュッセル・ウィーン・ベルリン・プラハといった高度に発展した首都圏と、スロバキア中西部・北ハンガリー・カスティーリャ=ラ・マンチャ・エストレマドゥーラといった社会経済的に不利な地域の双方が含まれた。さらにイスタンブールもEU首都圏とは異なるプロファイルとして浮上している。つまり『異常』は必ずしも悪い意味ではなく、EU全体のパターンから構造的に乖離していることを意味する。
論文が特に強調するのは、検出された異常が必ずしもデータ品質の問題を示すわけではなく、分析的・政策的に注目すべき『意味のある構造的乖離』である可能性がある点だ。これは統計機関にとって、機械的なデータ修正対象と政策分析対象を切り分ける運用上の示唆となる。フレームワークは完全再現可能・スケーラブルで、既存の欧州統計システムの検証ワークフローと互換があると明記されている。