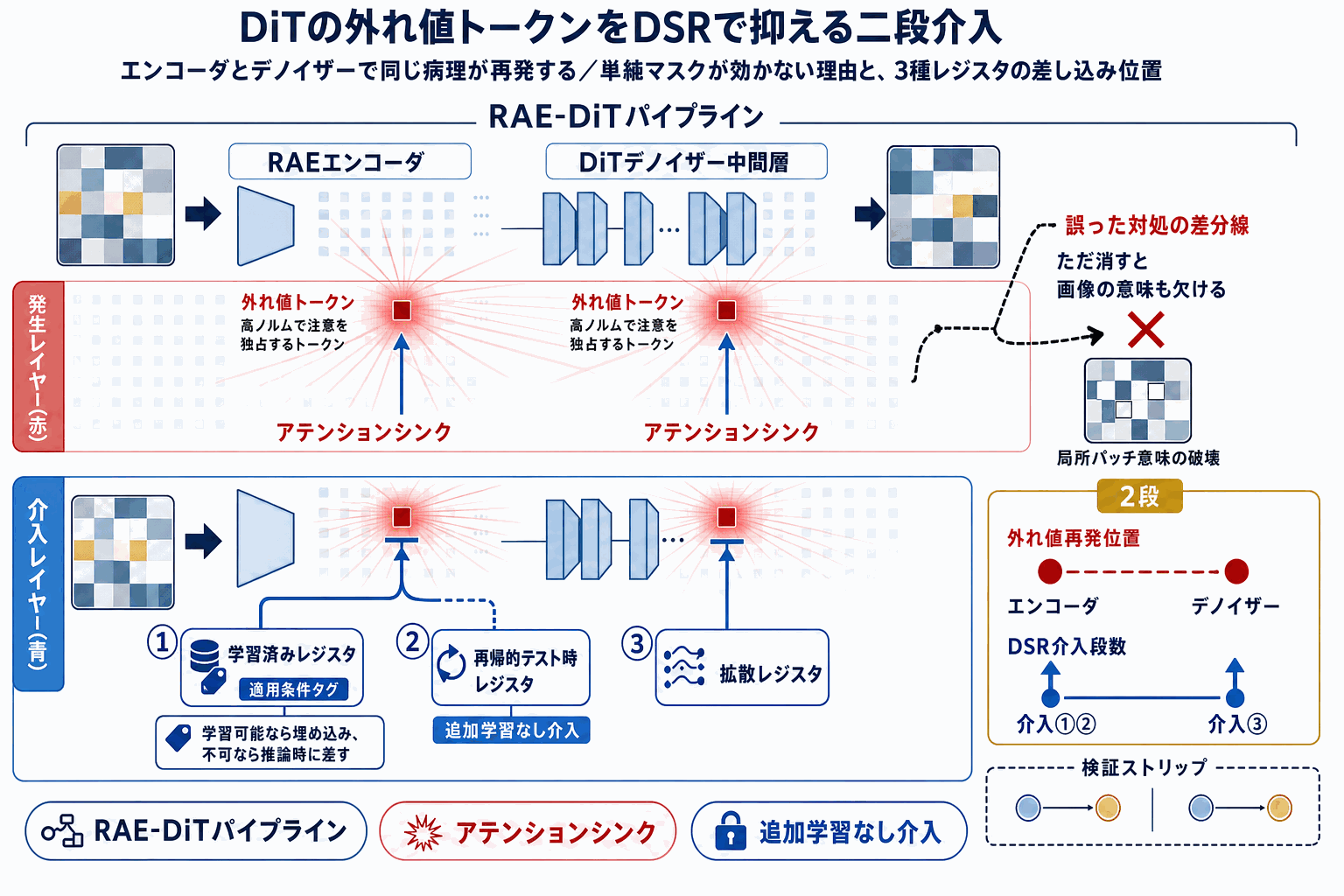
Vision Transformer(ViT)では、一部のトークンが異常に高いノルムを持ち、アテンションを不釣り合いに集める「外れ値トークン」現象が以前から知られていた。これらは局所的な情報をほとんど運ばず、アテンションシンクとして機能することが報告されてきたが、生成モデルにおける役割は十分に解明されていなかった。
本論文は、この現象が現代的なRepresentation Autoencoder(RAE)-DiTパイプラインの両端で発生することを示した。事前学習済みViTエンコーダが外れ値表現を出力するだけでなく、DiT自身も特に中間層で内部的な外れ値トークンを発生させる。注目すべきは、高ノルムトークンを単純にマスクしても生成品質が改善しない点だ。これは問題が「いくつかの極端な値」ではなく、「局所パッチの意味が破壊されている」ことに由来することを示唆する。
提案手法Dual-Stage Registers(DSR)は、両コンポーネントに対するレジスタベースの介入で、状況に応じて3種を使い分ける。学習が可能な場合は「学習済みレジスタ」、不可能な場合は「再帰的テスト時レジスタ」、そしてデノイザー向けに「拡散レジスタ」を導入する。ImageNetと大規模テキスト→画像生成の両タスクで、これらの介入が一貫してアーティファクトを減らし、生成品質を改善することが実験で確認された。
実装面では、テスト時レジスタが追加学習を要しない点が大きい。既存のDiTベースサービスに対し、推論パイプライン側での介入のみで品質改善を試せる余地があることを意味する。外れ値トークン制御は、より強力なDiTを構築する上での重要な構成要素として位置づけられた。