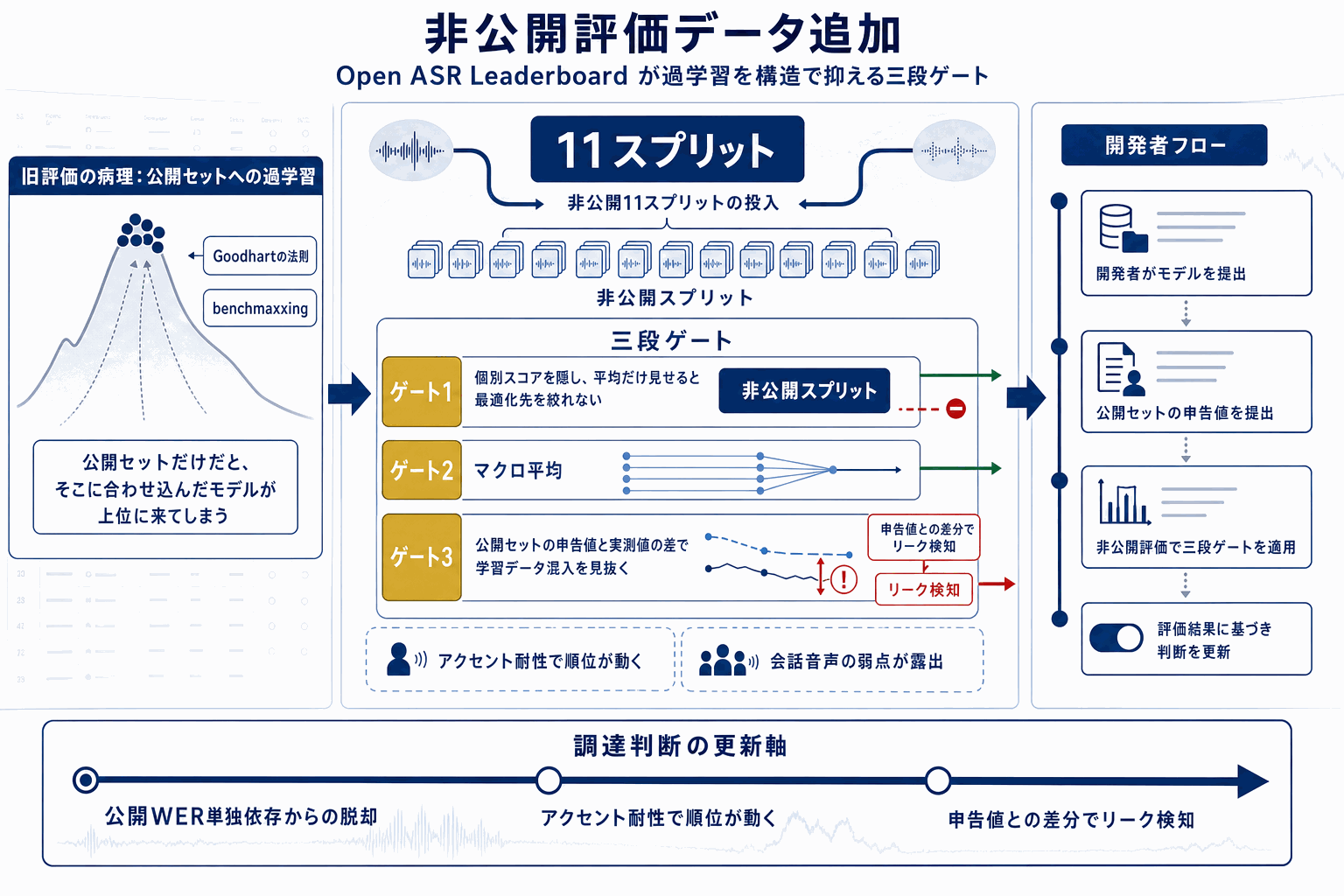
Hugging Face の Open ASR Leaderboard は、2023年9月の公開以来71万回以上閲覧されてきた音声認識モデルの標準的な評価基盤である。今回追加されたのは、Appen と DataoceanAI が提供する計11スプリットの非公開データセットで、豪州・カナダ・インド・米国・英国のアクセントを、スクリプト読み上げと自然な会話の両形式でカバーする。
特徴的なのは評価設計だ。非公開データの個別スプリットのスコアは公開されず、マクロ平均のみが提示される。これにより、特定のデータプロバイダーや特定のアクセントだけに最適化する「benchmaxxing(ベンチマーク最適化)」を構造的に抑制する。デフォルトの Average WER は従来通り公開データセットのみで算出され、非公開データはトグルで任意に追加する形式となる。
モデル追加の手順も整理されている。開発者は GitHub のプルリクエスト経由で申請し、公開セットの結果を申告した後、非公開セットでの評価が実施される。これは公開セットで結果を申告させることで、非公開セットとの差分からリーク(学習データへの混入)を検知できる設計でもある。
日本の開発現場への影響は明確だ。日本語 ASR は今回のスプリットに含まれないため直接の評価対象ではないが、音声認識モデルを選定する際の方法論として「非公開データを含むマクロ平均」という基準が標準化される。Whisper 系モデルや商用 API を比較調達する際、公開ベンチマーク WER のみに依拠した判断からの脱却が求められる。自社プロダクトで ASR を扱うチームは、評価基準の再定義を行うタイミングにある。