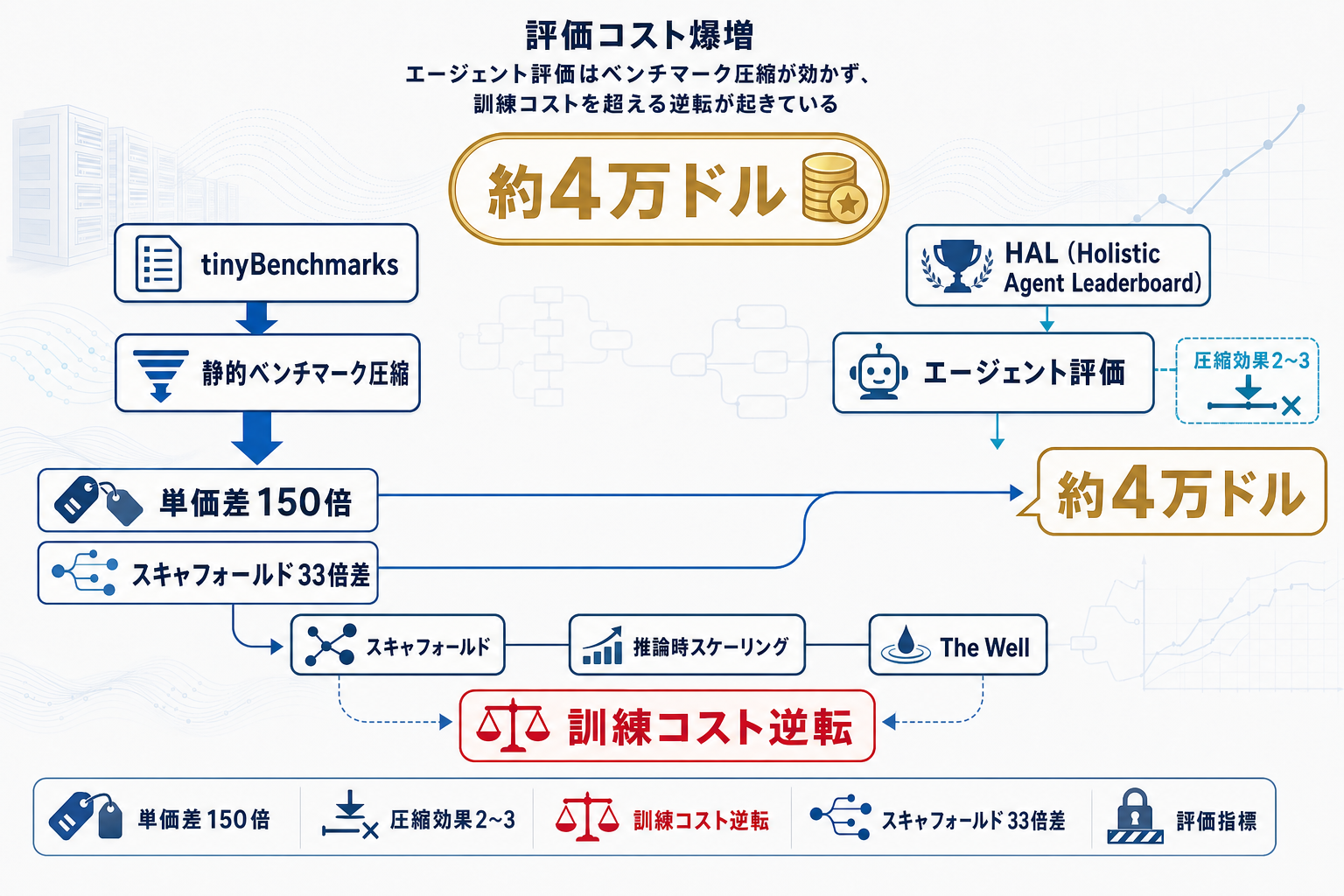
Hugging Face Blogが2026年4月30日に公開した分析記事「AI evals are becoming the new compute bottleneck」は、AIモデル評価にかかるコストが訓練コストや計算資源と並ぶ新たな制約要因になっていることを具体的な数値で示した。
中核となるのはHolistic Agent Leaderboard(HAL)の実測データで、9モデル×9ベンチマークに対する2万1730回のエージェント実行で約4万ドルが費やされた。物理シミュレーション向けベンチマークThe Wellでは、4ベースライン×16データセットのフルスイープに3,840 H100時間(約9,600ドル)が必要で、評価コストが訓練コストを約100倍上回る逆転が起きている。
コスト差の主因は二つある。第一にモデル単価で、Claude Opus 4.1の入力トークン単価はGemini 2.0 Flashの約150倍に達し、モデル選択だけで2桁の差が生じる。第二にスキャフォールド(実行環境)で、Online Mind2WebではBrowser-Use+Claude Sonnet 4が1,577ドルで精度40%、SeeAct+GPT-5 Mediumが171ドルで精度42%と、構成選択で9倍以上のコスト対性能逆転が観測された。
さらに深刻なのは、tinyBenchmarksやAnchor Pointsといった既存のベンチマーク圧縮手法が、静的評価では100〜200倍の削減が可能だったのに対し、エージェント評価では2〜3.5倍に留まる点だ。推論時スケーリングが評価コストに直接跳ね返る構造のため、大規模機関以外がフロンティアモデルを公平に評価することが困難になりつつある。AI調達・研究再現性・政策立案のすべてに影響する課題として提起された。