
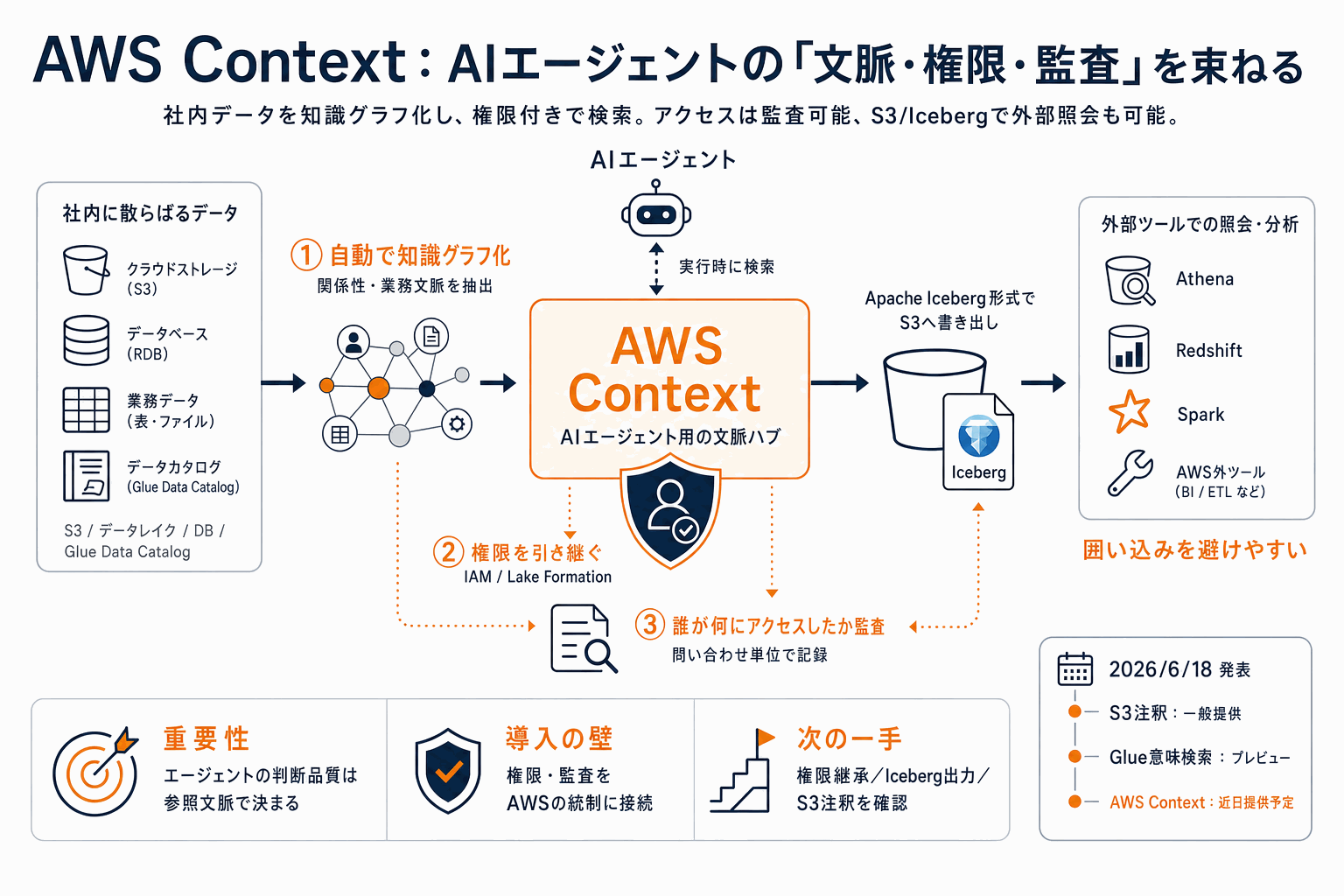
AWSは2026年6月18日、AWS Summit New York Cityにあわせて公式ブログで、社内データの関係性を自動で知識グラフ化しAIエージェントが実行時に参照できる新サービスAWS Contextを発表した。エージェントの判断品質は参照できる文脈の質に左右されるが、企業データはデータレイクやデータベース、ストリームに分散し、これまでは独自の取得パイプラインが必要だった。
実務上の要点は二つある。第一に、全ての問い合わせが利用者の権限(IAMおよびデータレイクの権限管理Lake Formation)を引き継ぎ、許可された関係性しか辿れず、誰が何にアクセスしたかを監査できる。基盤技術は個人向け知識グラフAmazon Quickで、同サービスは1日あたり数百万件の要求を処理している。第二に、文脈データは公開保存形式Apache IcebergでAmazon S3に書き出され、Athena/Redshift/Sparkなど互換ツールから照会・移行できるため囲い込みを避けられる。
提供時期は分かれており、Amazon S3注釈は正式提供開始、Glue Data Catalogの業務文脈・意味検索はプレビュー、AWS Context本体は近日提供となる。


The first chapter of enterprise AI was getting answers from data. The next chapter is turning governed data into governed decisions. Snowflake CEO @RamaswmySridhar and @Accenture's Rajendra Prasad share their perspective on the architecture of the agentic enterprise.…
Still running separate systems for transactions and analytics? That usually means clunky pipelines and lags. Snowflake Postgres changes that: ✅ Low-latency replication ✅ Always-fresh data ✅ Fewer moving parts 👉