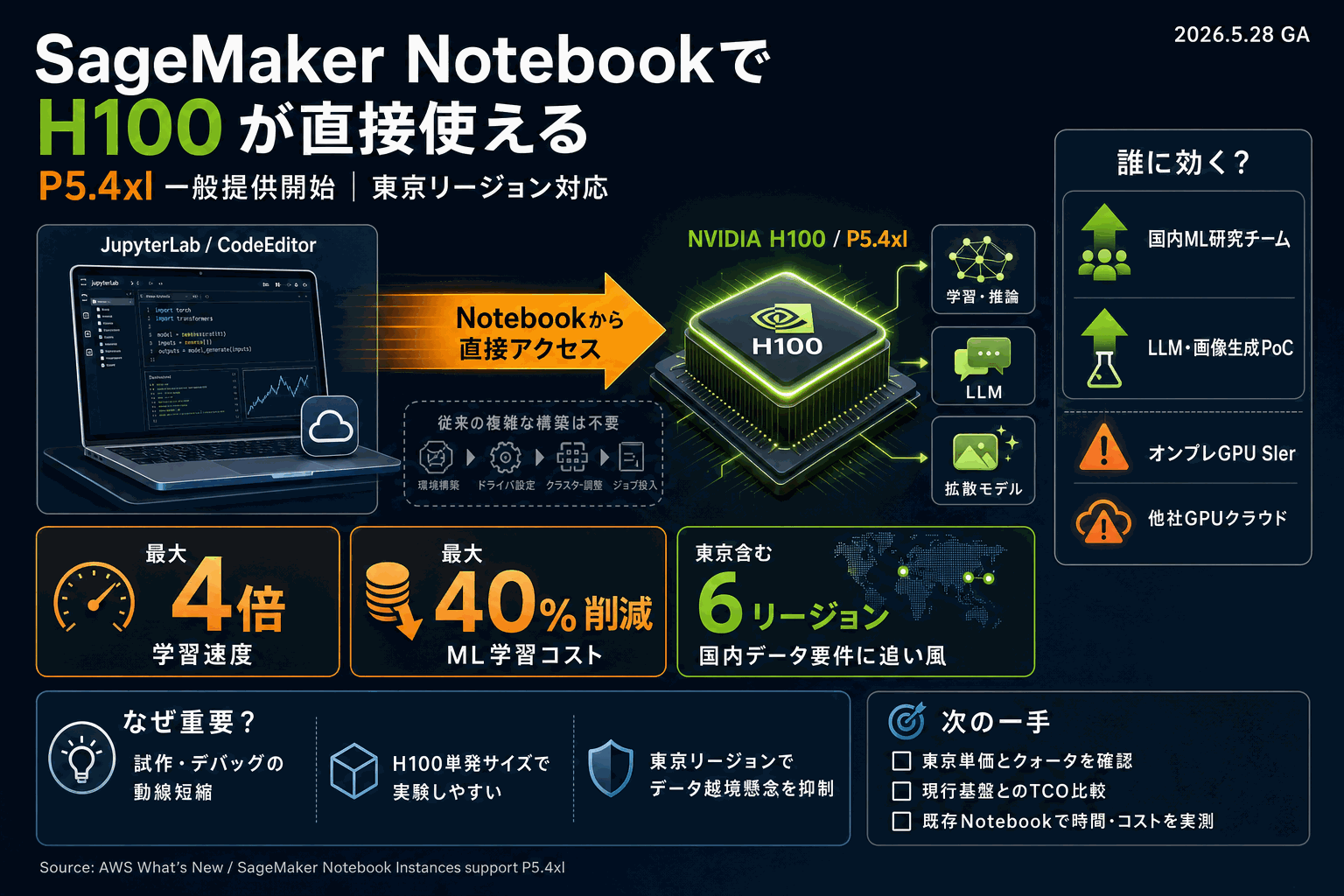
NotebookからH100を直接叩ける意味
AWSが発表したのは、SageMaker Notebook InstancesでAmazon EC2 P5.4xl インスタンスを一般提供(GA)開始したというもの。P5.4xlは NVIDIA H100 Tensor Core GPU を搭載し、ディープラーニングおよびHPC用途に向けた構成だ。AWSは前世代GPUインスタンスと比較して「解決までの時間を最大4倍短縮」「ML学習コストを最大40%削減」と公式に提示している。
これまでSageMakerでH100を使う場合、Training JobやHyperPodなどの仕組みを介する必要があり、JupyterLab上で対話的にH100を回す動線は限定的だった。今回のGAにより、Notebook Instances(JupyterLab / CodeEditor)から直接H100にアクセスできるようになり、LLM・拡散モデルの試作デバッグや小規模ファインチューニングのループが短くなる。
東京リージョン提供と業務適合の論点
提供リージョンは 米国東部(バージニア北部・オハイオ)、米国西部(オレゴン)、アジア太平洋(ムンバイ・東京・ジャカルタ)、南米(サンパウロ) の6つ。東京リージョンが初日から含まれている点は、国内データを越境させずにH100学習を行いたい案件で実装選択肢が増えることを意味する。
ユースケースとしてAWSは質問応答、コード生成、動画・画像生成、音声認識を挙げており、生成AIアプリのバックエンド開発を想定した訴求だ。実装着手時の落とし穴としては、P5系はクォータ申請が必要なケースが多く、Notebook起動の前にサービスクォータ確認を済ませないと「インスタンスを選んだのに起動できない」状態に陥りやすい点が挙げられる。コスト40%削減の数字はAWS側の比較条件に依存するため、自社ワークロードで実測してから既存基盤との置き換えを判断する流れが現実的だ。