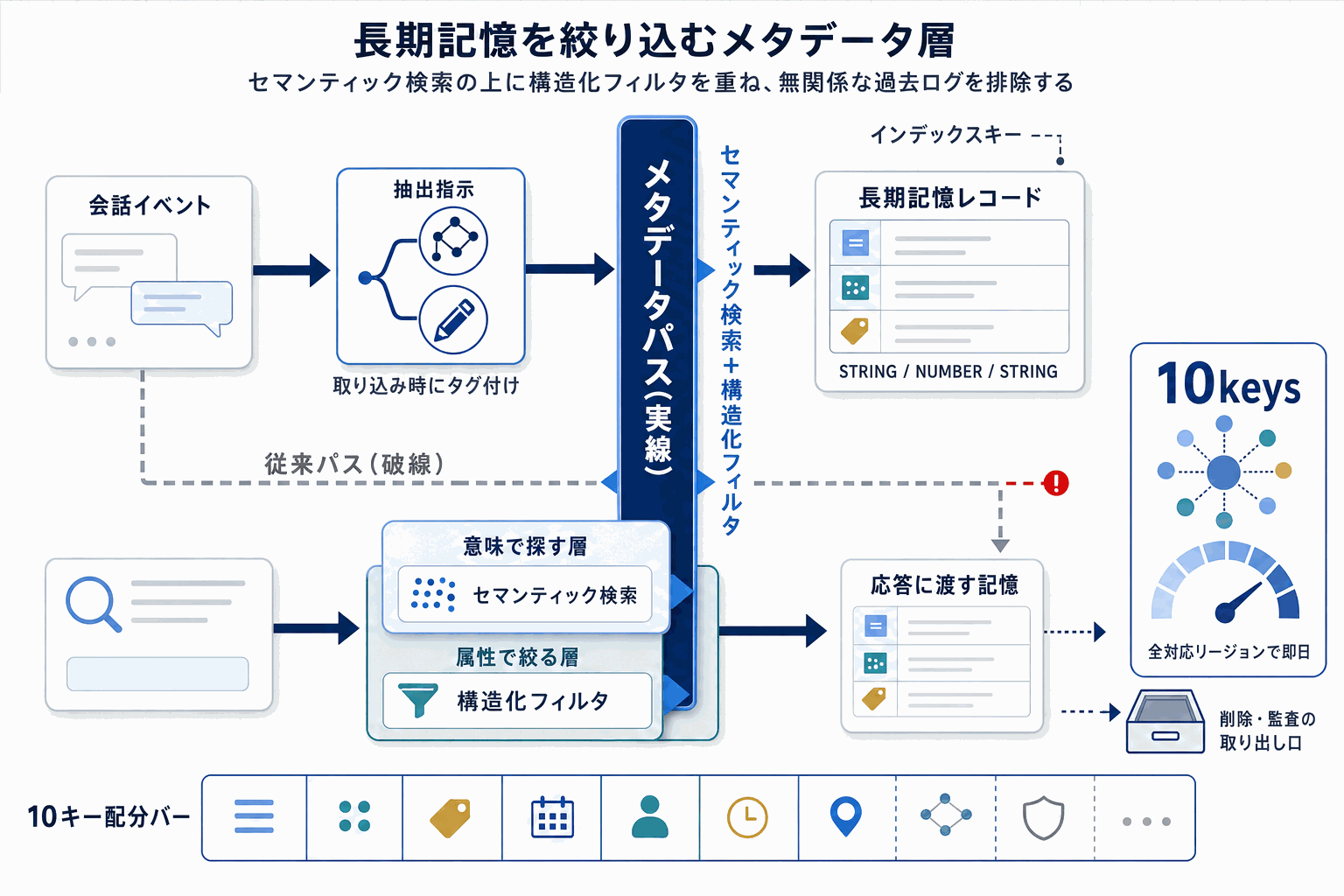
Amazon Bedrock AgentCore Memoryは、AIエージェントが会話履歴や知識を長期保持するためのマネージドサービスで、今回のアップデートで長期記憶(LTM)レコードに対するメタデータ機能が追加された。
仕組みは明快で、メモリリソースに対してインデックスキーのスキーマを定義する。キーは最大10個、型はSTRING・NUMBER・STRING_LISTから選択でき、必要に応じて許容値リストも指定できる。さらに抽出指示(extraction instructions)を併せて設定しておくと、イベント取り込み時にLLMが会話内容を解析し、どのメタデータをどう付与するかを判断する。開発者側でイベント投入時に直接メタデータを付けることも可能で、自動抽出と手動付与のハイブリッド運用ができる。
検索時には、セマンティック検索に加えて構造化属性でのフィルタリングが使える。公式ドキュメントで例示されているのはチケット番号、優先度、日付で、カスタマーサポートや業務自動化を強く意識した設計になっている。これにより、意味的に似ているだけの無関係な過去ログが混ざる問題を抑えられる。
実装着手時の落とし穴として、キー数が10個に制限される点は設計段階で意識したい。テナントID・ユーザーID・案件ID・ステータス・優先度・日付…と積み上げるとすぐに枠を使い切るため、どの属性を構造化キーにし、どれを本文テキストに残すかの切り分けが必要になる。加えて、LLMの自動抽出に頼り切ると許容値に収まらないラベルが混入することがあるため、allowed valuesを明示し、抽出精度を実データで測ることが現実的な進め方となる。全サポートリージョンで即日利用可能なため、既存のAgentCore利用者はすぐに評価に着手できる。