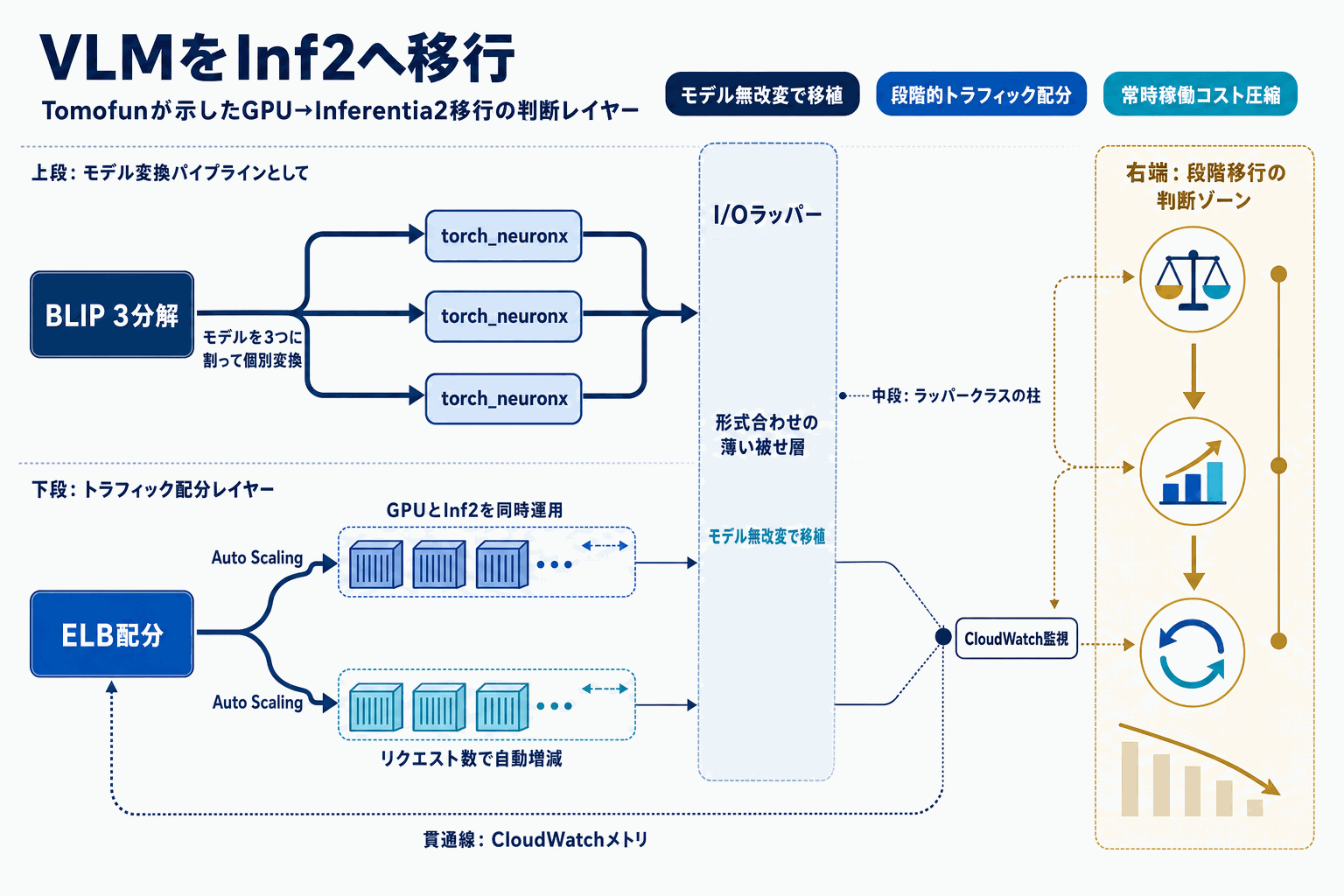
AWS Machine Learning Blogが、台湾発のペットテック企業Tomofun(Furbo Pet Cameraの開発元)によるVLM推論基盤の移行事例を公開した。対象はペットの行動を検知するために使われるBLIP(Bootstrapped Language-Image Pretraining)モデルで、常時稼働型のリアルタイム推論におけるGPUコストを抑える目的で、EC2 Inf2インスタンス(AWS Inferentia2搭載)への移行が進められた。
実装面の核心は、BLIPを画像エンコーダ・テキストエンコーダ・テキストデコーダの3コンポーネントに分解し、それぞれをtorch_neuronxで個別にコンパイルした点にある。そのうえで軽量ラッパークラスを挟んでI/Oフォーマットを変換することで、BLIPの事前学習済みロジック自体には手を入れずにInferentia2上で動作させている。モデル本体の改変を避けるこのアプローチは、VLMを専用アクセラレータへ載せる際に発生しがちな互換性問題への現実的な解となる。
インフラ側は、ELBとEC2 Auto ScalingグループによってGPUコンテナとInf2コンテナへのリクエストをリアルタイムに切り替えられるハイブリッド構成を採用している。Amazon CloudWatchでレイテンシ、スループット、エラーレートを監視し、リクエスト数をメトリクスとしてAuto Scalingを制御する。全面移行ではなくトラフィックを分配できる点が特徴で、段階的な検証と切り戻しを前提とした運用設計になっている。
常時稼働型推論を抱える事業者にとって、本事例はGPU依存から抜ける際の実装テンプレートとして参照価値が高い。特にPyTorchベースのTransformer系モデルを扱うチームは、分解コンパイルとラッパーによるI/O整合という2点を自社モデルに当てはめて検証することで、移植可否を早い段階で切り分けられる。