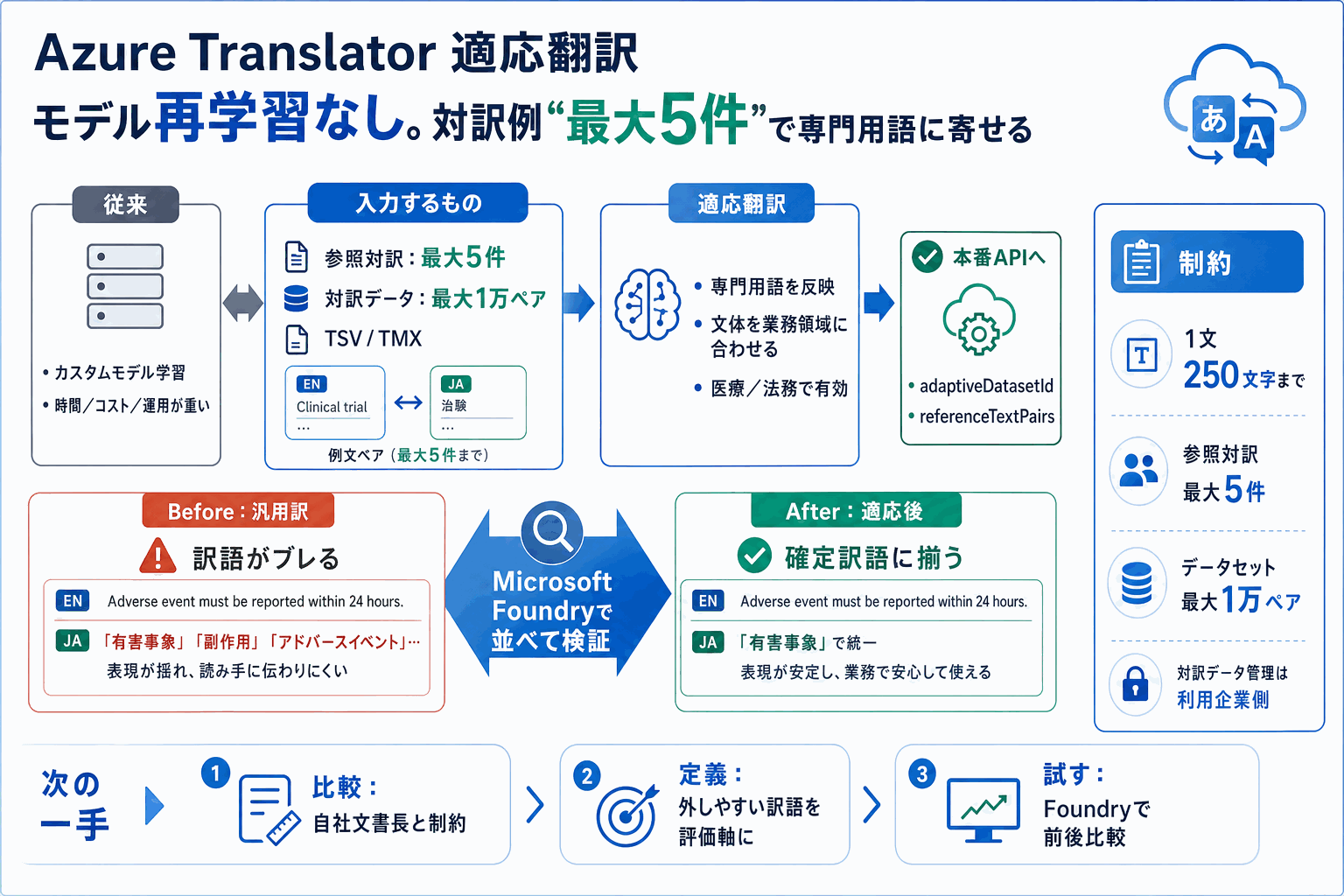
MicrosoftがAzure Translatorに「適応翻訳(adaptive translation)」を追加した。汎用の大規模言語モデル(LLM)による翻訳は流暢でも医療・法務など分野特有の用語を外す弱点があったが、この機能はモデルの再学習なしで専門用語や文体を反映できる。
仕組みは少数事例学習(Few-Shot Learning)の応用で、与え方は2通り。最大5件の参照対訳(referenceTextPairs)を直接添える方法と、最大1万ペアの対訳データセット(adaptiveDatasetId)を登録してIDで指定する方法がある。データセットはTSVまたはTMX形式のファイルから作成でき、原文・訳文とも1文250文字を超える例は非対応という制約がある。
本番適用はTranslate APIで`adaptiveDatasetId`か`referenceTextPairs`を指定して行う。Microsoft Foundryの試用環境で適応前後の訳文を並べて比較できるため、アプリへ組み込む前に効果を検証でき、導入の意思決定がしやすい。