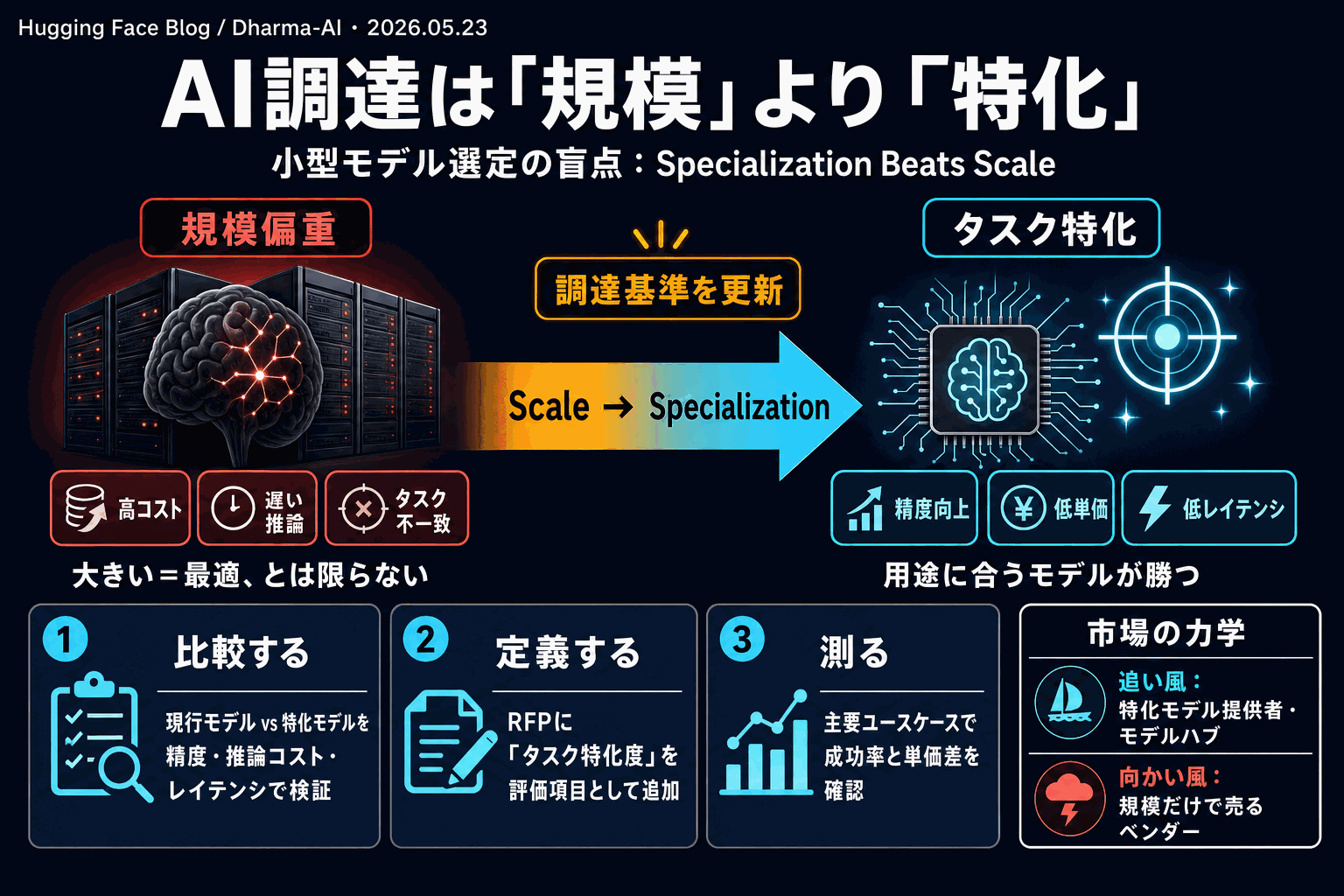
何が提起されたのか
Hugging Face Blog上でDharma-AIが公開した「Specialization Beats Scale」は、AI調達の現場で繰り返される「より大きなモデルほど良い」という前提に異議を唱える論考だ。著者は、モデル規模(パラメータ数・ベンチマーク総合スコア)が調達の主要評価軸として独り歩きする一方、タスク特化度という戦略変数が見落とされていると指摘する。
Specialization Beats Scale: A Strategic Variable Most AI Procurement Decisions Overlook
日本の調達現場への含意
国内企業のAI導入でも、フロンティアモデルの総合ベンチマーク順位を根拠にベンダー選定するケースが目立つ。だが特定業務(契約書レビュー、コールセンター要約、製造現場の異常検知など)では、ドメイン特化の小型モデルが汎用大規模モデルを上回る精度を出しつつ、推論コストを大幅に下げる構成が成立しうる。本記事はその構造を「調達フレームの欠落」として整理した点に意義がある。
他社事例との比較と落とし穴
MercariやLINEヤフーが社内RAG/特化LLMを検討する際、ベース選定でフロンティアモデルと小型OSS特化モデルを並走評価する事例は公開資料でも散見される。一方で、調達RFPの評価項目に「タスク特化度」を明示している企業は少ない。実装着手時の落とし穴は、特化モデルの強みを示すには自社タスクに沿った独自評価セットが必須で、公開ベンチマークだけでは特化の優位性が見えない点だ。コスト面ではソース内に具体数値の記載はないため、自社環境での実測比較が判断材料となる。