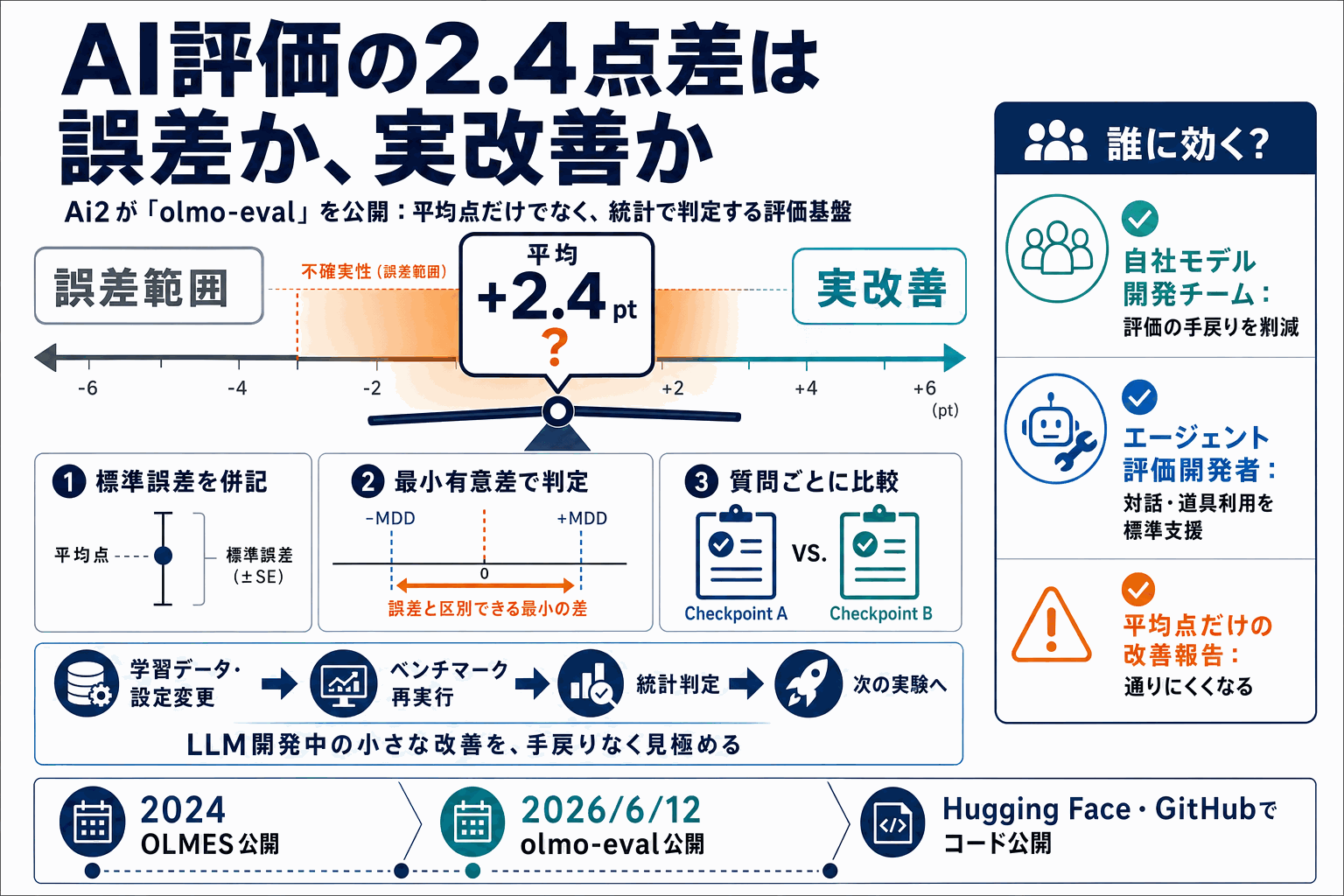
AI研究機関のAi2が2026年6月12日、開発中の大規模言語モデル(LLM)を繰り返し評価するための作業環境「olmo-eval」をHugging Faceブログで公開した。同社が2024年に出した評価標準「OLMES」を土台に、ベンチマークの追加・実行・比較を素早く回せるよう開発工程全体へ拡張したものである。
最大の特徴は、各スコアに標準誤差と『誤差と区別できる最小の差』を併記する点にある。平均スコアが2.4ポイント動いたとき、それが本当の改善か単なる誤差かを判断できる。質問ごとに2つのチェックポイントを並べて比較し、平均値が隠す小さな変化を見える化する。
設計面では、課題・実行方法・道具・採点補助モデルを差し替え可能な部品として扱える。軽い評価はそのまま実行し、コード実行など隔離が必要な評価のみコンテナで動かす二段構えとし、対話型・道具利用型(エージェント)の評価も標準機能として支援する。コードはオープンに公開され、自社モデルを開発する組織が評価の手戻りを減らせる。