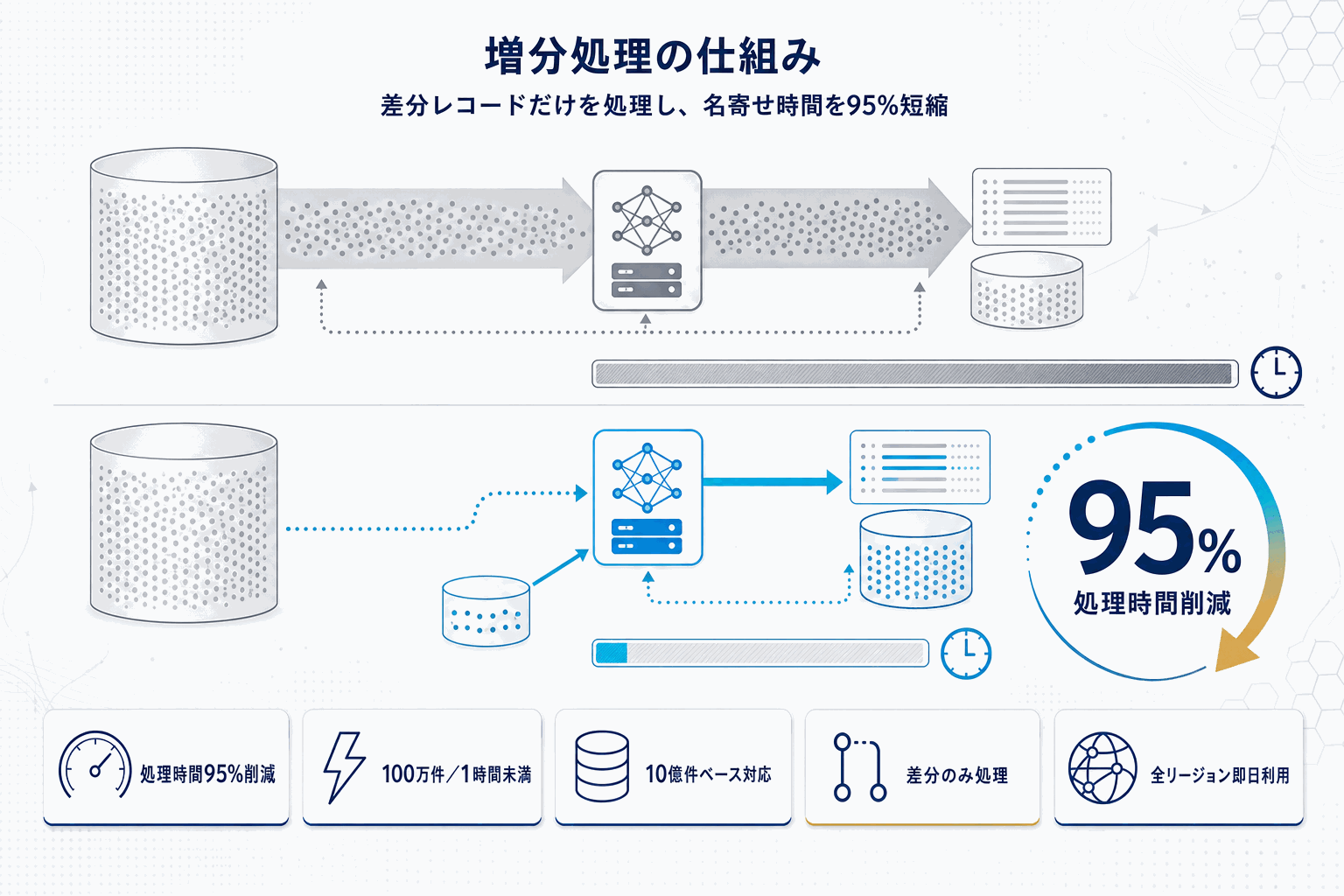
AWS Entity Resolutionは、複数のデータソースに散らばった同一顧客・同一エンティティのレコードを突き合わせる、いわゆる「名寄せ」サービスだ。今回のアップデートの核は、MLベースのマッチングワークフローに増分処理(Incremental Matching)がGAとして追加された点にある。
これまでは、1件の新規レコードを追加するだけでもデータセット全体を再処理する必要があり、最大2日・数千ドルのコストがかかるケースがあった。この構造が、日次で顧客が増えるCDPやマーケティング基盤にとって深刻なボトルネックになっていた。増分処理では、前回実行以降に追加されたレコードだけを対象にするため、100万件の増分を1時間未満で処理でき、従来比95%の処理時間削減となる。
対応スケールも具体的に示された。最大10億件のベースレコードを持つデータセット上で、最大5000万件の増分レコードを処理できる。この数字は、エンタープライズCDPや広告配信用の顧客基盤がそのまま載るレンジで、これまで経済合理性の観点で選外になりがちだった継続的な大規模名寄せが現実的な選択肢に入る。
読者の実務判断としては、(1)自社の総レコード数と日次増分が上限内に収まるかの確認、(2)既存の自前名寄せやSnowflake・Databricks上の実装とのコスト・鮮度比較、(3)PoCでの処理時間・精度計測、の3点が当面のアクションになる。提供はEntity Resolutionが利用可能な全AWSリージョンで、追加の地域制限なく着手できる。