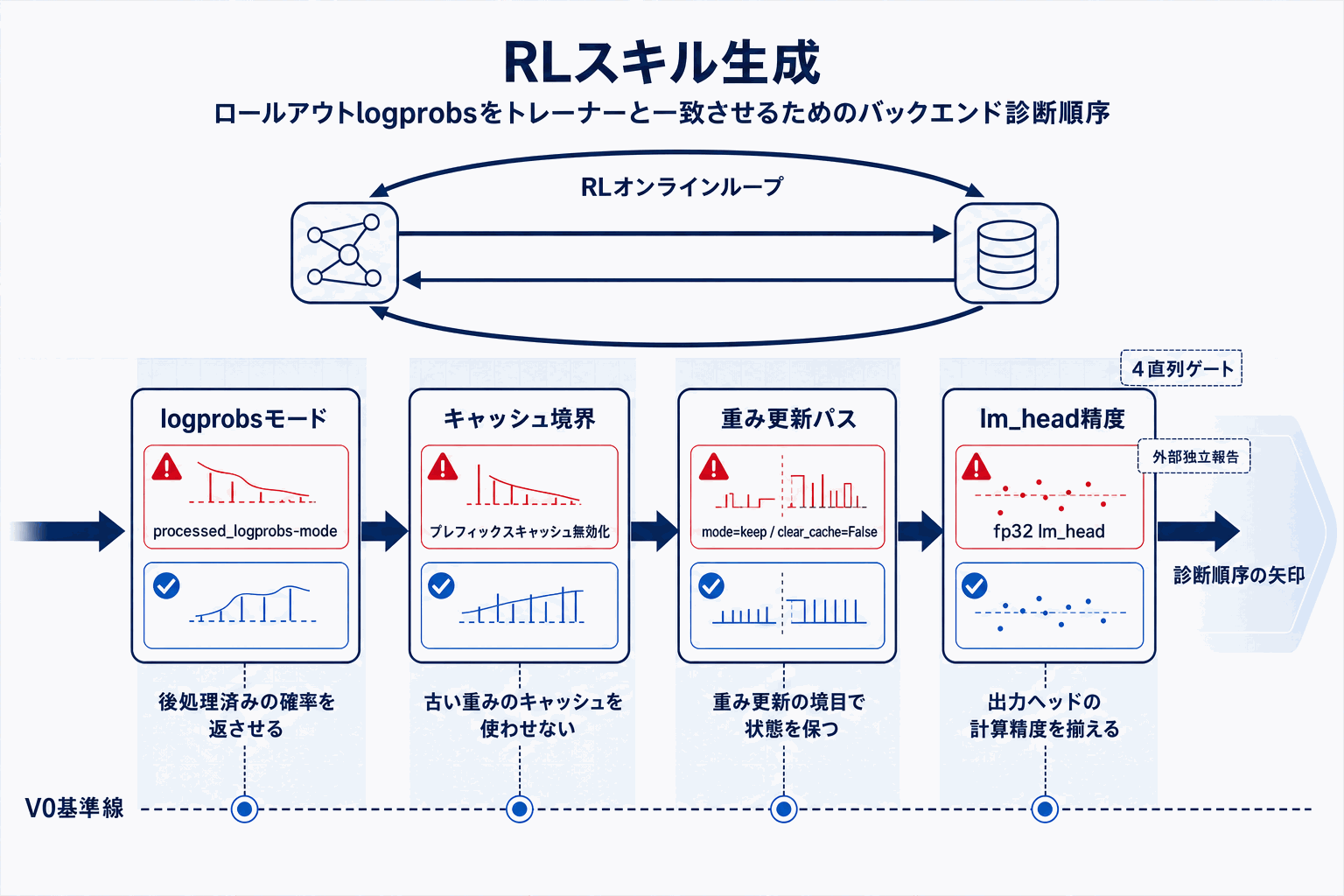
ServiceNow AIチームは、vLLM V0からV1への切り替え時にオンライン強化学習の正確性が崩れる現象について、原因を4つに整理した技術ブログを公開した。ポイントは、RL目標側を触る前に推論バックエンドの正確性を先に確認せよという診断順序にある。
第一に、V1はデフォルトで生logprobs(温度スケーリング等の後処理前の値)を返す。RLではトレーナーとロールアウト側で同一のlogprobsが必要なため、`logprobs-mode=processed_logprobs`を明示する必要がある。第二に、プレフィックスキャッシュが有効な状態では、モデル重みの更新境界をまたいで旧重みでのキャッシュが再利用され、新しいポリシーのlogprobsと整合しなくなる。
第三に、インフライト重み更新の挙動がV0とV1で異なる。V1では`mode='keep'`かつ`clear_cache=False`を指定することで、V0相当の挙動に近づけられる。第四に、トレーナーとロールアウトバックエンドでlm_headの計算精度を揃える必要がある。fp32での一致が最終的なlogprobsパリティの条件であり、この論点はMiniMax-M1の技術レポートやScaleRL論文でも独立に報告されている。
意思決定への含意は明快だ。RL学習が収束しない、報酬が想定通り伸びないといった症状に直面したとき、損失関数やKLペナルティの係数を触る前に、推論エンジン側の4設定を確認する。バックエンドの正確性が担保されて初めて、RL目標の修正が有効な介入となる。V1への移行を計画するチームは、PipelineRLの公開実装を参照しつつ、移行前後でtoken単位のlogprobs差分を測るチェック手順を整備しておきたい。